
|
|
1.IntroductionVisual search is one of the critical technologies in the field of computer vision; it can support high-level applications such as motion analysis, image understanding, and so on. It is a common task to find specific objects in the scene that have been roughly three-dimensional (3-D) modeled by methods such as simultaneous localization and mapping (SLAM)1 or structure from motion (SFM).2 In these scenarios, location information can be supplied by sensors such as global position system in the outdoors or RGB-D in the indoors. Corresponding 3-D-coordinates of some image pixels can be calculated by triangulation methods.3 For this case, we refer to rough 3-D-modeling scenes. The specific target is usually hard to discover owing to complex natural scenes that contain similar distracters. A feasible way to find the specific target is through the positions of the salient objects in the same scene. Intuitively, given a known point in the rough 3-D-modeling scenes, the search region in the image of the target will be decreased. In this paper, we build an optimization model for this issue based on a camera imaging model. Through this optimization method, we calculate the search regions of the other points when a two-dimensional (2-D)–3-D point pair is found. Brief reviews about camera imaging models are depicted in Sec. 3.2.1. The salience computation model was first proposed by Itti et al.4 Until now, Itti’s model was still competitive with current state-of-the-art methods.5 In Itti’s model, salience measurements of visual features are computed according to the local contrast principle. Then, the salience values are sorted in descending order. Finally, a visual search path of features is formed. Itti’s salience model and the subsequent improved methods focus on salient object detection or fixation prediction.6 In this type of search path formed by these methods, features are independent from each other and relations of features are not taken into account. By those methods mentioned in Ref. 6, the nonsalience objects cannot be found according to their salience estimation. Actually, relations exist among visual features, which are confirmed in Ref. 7. In this paper, our salience model is designed so that the salience measurement is computed with respect to the search region. Features can be analyzed quantitatively in the specific search region. The search region is decreased if a salient feature is found in rough 3-D-modeling scenes. In the decreased search region, nonsalient objects can become salience and be localized. We propose a visual search method based on vision salience theory and a camera imaging model, which performs rapid and accurate object locating along a visual search path. This search path takes account of the relations of visual features. Consider the problem that we want to find the coin in the dot line circle, as shown in Fig. 1, which contains the colinear key and battery, the cluster of coins, and so on. If we seek the coin in the whole image by the traversal algorithm, it is inefficient and easily affected by clutter like similar objects. However, we will carry out the visual search along the path as follows: first, the key in the solid line circle; second, the button cell in the dash line circle; and last, the coin in the dot line circle. At each step, we actually detect the salient object in the given region. More notably, the search region of each object along the path is decreased gradually. Owing to the operations of this model, we can (i) estimate the saliency of features in the given search region; (ii) eliminate the effect of similar distracters in the background; and (iii) decrease the search region to improve the salience of features. Fig. 1An example of search path. The target is the coin in the dot line circle. The search path is composed as follows: first, the key in the solid line circle; second, the button cell in the dash line circle; and last, the coin in the dot line circle.  There are six sections in this paper. In Secs. 1 and 2, we give the introduction and related works. In Sec. 3, first we introduce the definitions of saliency and search path used in this paper. The two concepts instruct how to find the specific object. Second, we present the method of how to calculate the search region of features along the search path. We illustrate how a feature that has been found affects the subsequent features along the path according to the optimization model. Third, we describe the whole algorithm process. Details of the algorithm reveal the formulation of a search path that arrives at the final target. In Sec. 4, we give the experiments to demonstrate the effectiveness of our method. In Secs. 5 and 6, we propose some directions for future work and conclude our paper. 2.Related WorksSaliency is an important part of the overall process of lots of applications. Recently, researchers attempted to learn and utilize human visual search to guide salience computational mechanism.8,9 In Itti’s model, saliency of visual features is computed by means of center-surround mechanism, which is an implementation of local contrast. Information theory, Bayesian inference, graphical models, and so on are also introduced to represent local contrast and calculate saliency by other researchers. Bruce and Tsotsos10 presented a salience model in which self-information of local image patch is used to determine the salience measure. Hou and Zhang11 utilized incremental coding length to select salient features with the objective to maximize the entropy across sample features. Li et al.12 defined the saliency as the minimum conditional entropy given the surrounding area. The minimum conditional entropy is further approximated by the lossy coding length of Gaussian data. Butko and Movellan13 built probabilistic models of the target, action, and sensor uncertainty, and used information gain to direct attention to a new location. Gao et al.14 considered the discriminant saliency as a one-versus-all classification problem in which kullback-leibler divergence is used to select salient features. Zhang et al.15 presented a Bayesian model to incorporate contextual priors in which the overall saliency is computed by the pointwise mutual information between the features and the target. Harel et al.16 presented a fully connected graph over all pixels, which is then treated as a Markov chain to obtain the salience value. Chikkerur et al.17 designed a Bayesian graph model that combines the spatial attention and feature-based attention. However, research on the salience computational model is still in a fledging period. Most work, including the methods aforementioned, concentrates on using or modifying the salience model proposed by Itti et al.6 because all saliency systems can be seen as a local contrast computation model.5 Computing local contrast is an essential step for saliency estimation.5 Whether objects are salience or not is determined by their difference from the surrounding area. Given the surrounding area, the methods aforementioned are only designed to produce static salience estimation. Relations of features beyond the appointed local scope cannot be taken into an account. As a result, the salience estimation cannot provide evidence to locate nonsalient objects. Our method is still based on local contrast; however, we calculate the local contrast of features by making use of the search region. The search region can be computed dynamically to improve the salience of features. 3.Method FormulationIn this section, we describe the details of our method and propose an algorithm that generates a search path guiding to the target. In this paper, the following notations are required to describe a 3-D scene. 3.1.Region-Based Salience AnalysisIn this paper, we take advantage of the visual search mechanism to find the salient objects preferentially, so we can improve the search speed and accurate rate. First of all, we give the definition of the salience of objects used in our paper and the method how to calculate it. Definition 1.Given scene image , search region , and feature , the salience measurement of object with respect to , , and is Given scene image , search region , feature , and threshold , is a salience object, indicated by , with respect to region if and only if Threshold is determined by detection rate.In Definition 1, we define the salience of objects with the method of Bayesian maximum likelihood. For example, similar features are located in the same search region. The salience measure of a specific feature is . If feature is unique, i.e., , the salience measure of is the defined max value. On the contrary, the salience measure of will become small. Compared with common objects, salience objects are more discriminable and different from their background. As a result, they can be detected with a higher accuracy rate. According to Definition 2, the search process proceeds along a path composed of salient object → salient object →⋯→ target. The search path performs the target search through locating salient objects step by step. In this search path, the closer to the target, the smaller the search regions of the salient objects become. Areas of search regions are determined by the previous found features, which are depicted in Sec. 3.2. Through such operations, we can make use of relations among features. Proposition 1 shows that in a shrunken region salient object is still salience. This proposition guarantees that we can determine a salient object in a large region. As a result, the effect from the previous features, which makes the region shrink, can be utilized correctly. Each node of this path confirms the position of one salient object and then reduces certain degrees of freedom of the object search. Then search regions of subsequent nodes of the search path decrease as they get close to the specific target gradually. Based on Definition 1, the smaller the search area, the more salience the object is. With the forward of a search path, the target becomes easier detect. 3.2.Search Region3.2.1.Pinhole camera modelCamera imaging model is used to project points in a 3-D world coordinate system to points in a 2-D image coordinate system.18–20 The pinhole camera model is used in this paper. This model can be described as where is the coordinate of a point in the world coordinate system, is the corresponding coordinate in the image coordinate system, is the intrinsic parameter matrix, and is the extrinsic parameter matrix. Matrix can be denoted as which is calibrated in advance and fixed during processing. Matrix can be denoted as where and3.2.2.Search regionGiven a search path , which comprises a serial of features, the search region of is determined by these factors including position and pose parameters from sensor measurements and the found features. We denote position and pose parameters with and measuring errors with . Features that have been found are denoted as , with corresponding 2-D image coordinates and corresponding 3-D coordinates . The search region of with world coordinate is generated by the equation where the operator Range is defined as . Operator Range depicts the imaging range of . Obviously, the search region of is only determined by the position and pose parameters as well as the errors of sensor measurements.In Eq. (7), matrix is expressed as . The incremental quantity varies in the range . When an object is localized, how does the search region of the next object change? This question can be formalized as In Eq. (8), the optimized objective function contains a nonconvex function such as a trigonometric function. It is intractable to solve this type of issue. One way to solve Eqs. (7) and (8) is the brute force method in which way values of independent variables are substituted into the objective function iteratively in a specific step size. However, according to Weierstrass’ theorem,21 for any continuous function defined on a bounded closed interval , there exists a polynomial function such that for all and every . For Eq. (4), it is composed by elementary functions only, so it can be approximated by a certain polynomial function. We expand Eq. (4) using first-order Taylor polynomial at the point , and then we have where is Jacobi matrixAccording to Eq. (9), Eq. (8) turns into the linear equation with linear constraint condition after omitting the high-order term . This equation can be solved efficiently because its extreme value is achieved on the endpoints of the bounded closed interval of the feasible region. In this paper, we adopt a simplex method to solve this problem. 3.2.3.Remainder analysisIn Eq. (9), there also exists a remainder term that needs to be considered further. Functions , , and have the similar expression form that they all comprise a trigonometric function with respect to , , and , and a linear function with respect to , , and . Without loss of generality, we only analyze the remainder term of . The Taylor expansion of on interval is where is the gradient function of , is the Hessian matrix of , and locates in the interval .Further on we have . Operator involved in this paper is two-norm. According to the property of two-norm, we have . The value depends on because of . In this paper, we approximate with . The maximum eigenvalue of a matrix can be calculated by the power method that is shown in Appendix A.1. Details of the difference between and is shown in Appendix A.2. So the remainder can be expressed as Actually, the difference between and can be neglected to provide concise computation while preserving sufficient precision.3.3.Algorithm for Search PathIn this section, we present the algorithm that generates the search path based on the discussion above. The following pseudo code in Algorithm 1 is the procedure to perform the target search. By this algorithm, we will obtain the evaluation result whether we can find the specific target or not. Because the algorithm is somewhat complicated, we give the corresponding graphical illustration in Fig. 2. Figure 2 shows the main procedure of Algorithm 1. Algorithm 1Search path generation.
Fig. 2The main procedure of search path. Through the input image and sensor measures, the target can be determined whether it could be found or not by Algorithm 1. 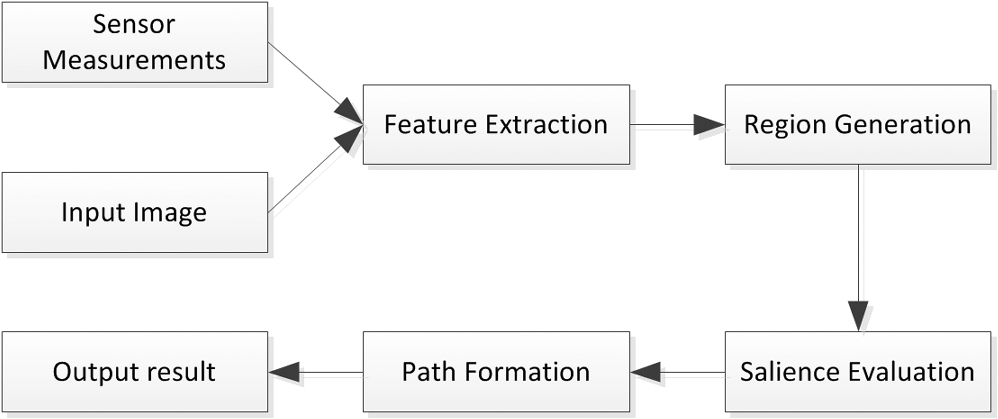 4.Results and DiscussionsIn Sec. 4.1, we demonstrate the superior performance of our salience model qualitatively by comparing it with two classic salience models, Itti’s model4 and Cheng’s model.22,23 In Sec. 4.2, we show how the proposed algorithm proceeds to form the search path. During this procedure, we also illustrate that the search regions of objects can be computed quantitatively and the target can be judged whether it is salience or not. 4.1.Saliency-Based Scene AnalysisIn this section, we compare our salience model to Itti’s model and Cheng’s model for the aim of scene analysis. Itti’s model is based on local contrast with the objective to calculate the salience measure of image pixels or patches. Cheng’s model is based on global contrast with the objective to segment the salient object from the image. Although Itti’s model4 was published early, this model is still competitive with current state-of-the-art methods.5 Cheng’s model,22 published more recently,23 proves that it outperforms other methods of the same type. All the image patches of this experiment are acquired from Affine Covariant Features Database.24 The feature is constructed with the values inside a rectangle centered at the location of the local maximum response of difference of Gaussian. We compute the salience measurements of the image patches for the three methods. The results are shown in Fig. 3, in which the higher level of saliency, the brighter the objects are in the image and the more discriminative power they have. Fig. 3The comparison of salience models: (a) original image patch, (b) Itti’s saliency model and (c) our saliency model, and (d) Cheng’s model. The higher level of saliency, the brighter the objects are and the more discriminative power they have.  In the scene that contains similar objects, the feature of these objects appears more frequent than that in the scene that only contains unique objects. As a result, the term is greater for the scene that contains similar objects than that for the scene that only contains unique objects. For the first row of Fig. 3, because of the existence of windows with similar appearance, our model gives a lower level of saliency than Itti’s. This result is intuitive because this image patch can hardly be used for visual search. For the second row, our model gives a higher level of saliency for the image patch because this patch contains the unique object like the tower. For Cheng’s model, it outputs a different kind of result because a different mechanism, global contrast, is adopted. For the first row, Cheng’s model captures two windows successfully. But for the second row, this model fails. According to the results, our salience model can provide more valuable evidence for visual search in these scenes. 4.2.Visual SearchIn this section, we leverage the real environment to test the validity of our method. The images are acquired from New York University (NYU) Depth Dataset V2 Dataset.25 The experiment scene is shown in Fig. 4. The size of images is , and the depth images provide the 3-D coordinates. We utilize Harris corner as the feature to represent objects. The unit of distance is meter, and the unit of angle is degree. The coordinate of the camera is (0, 0, 0), and the pose parameter is (0, 0, 0). The target, a bottle, is indicated by a cross with coordinates (, 0.1873, 1.323). Because of the synchronization of RGB frames and depth frames and other measure noises, the error is derived as (0.5, 0.5, 0.5, 0.1, 0.1, 0.1). Fig. 4The experimental scene. The target is indicated by a cross and the search region is indicated by a rectangle.  In the first step, Harris corners of the image are extracted as features, which are presented by circles in Fig. 4. Owing to the corresponding 3-D coordinates, the search region can be obtained according to Eq. (7) and indicated by a rectangle. From the result, the target cannot be found because there are objects that have a similar appearance, whichs lead to a low level of saliency. In the next step, the search path is generated to locate the target. During this processing, we need to select the salient features and judge whether the target can be found or not. In this experiment, the first salient feature is selected with coordinates (0.1363, 0.1131, 1.487), which is shown in Fig. 5 using circle. The critical step for generating the search path is the computation of the search region when a feature is located. When the feature at the starting point of the search path has been found, the search regions of other features are calculated by Eq. (8). When more features are found, the search regions of other features are calculated in the same way. The second feature is selected with coordinate (0.8518, , 2.5), which is shown in Fig. 6 using circle as well. The salient objects are found preferentially, and then the target can be searched in the new search region. Fig. 5The intermediate generated search path. Through locating one salience object, the search region of the target decreases.  Fig. 6The final generated search path. Through the salience objects, the target can be found in the new search region.  When two salient objects join the search path, the target can be found in the new search region. According to the algorithm proposed in our paper, a search path is generated as is shown in Fig. 6 using arrows. Quantitative results are shown in Table 1. We can see that as the number of salient objects increases, the search region of the target decreases and the target becomes easier to be found. Table 1Generation of search path.
In Table 2, we list the performance comparisons of the computation involved in Eqs. (7) and (8). The speed of the target search can be improved by 56.7% using the optimization method compared with the Brute Force method. The results are obtained on a PC with Intel I5 CPU and 8G RAM. Brute force is executed such that position parameters are substituted iteratively in a step size of 0.05 and pose parameters in a step size of 0.1. The unit of error is subpixel, which is the max error value in width and height. We can see that approximation, and optimization has excellent running time while keeping an acceptable error. Note that we consider that brute force has the most accurate result subjectively. If we want to improve the accuracy of brute force further, a smaller step size is needed and the running time grows exponentially. More results can be found in Fig. 7. The targets are the can, the cup, and the book. The search paths that lead to the targets are shown in the second row of Fig. 7. Table 2Performance comparisons of brute force, approximation, and optimization.
5.Future DevelopmentsThis paper applies key point features for salience estimation. In the future, we will use more features such as color and texture to improve salience estimation. The known knowledge of objects is also a benefit of salience estimation as a top–down tune. We will attempt to model the prior knowledge and integrate them into our salience estimation method. In Sec. 3.2.2, a simplex method is applied to determine search regions. However, this method is time-consuming, especially when a nonlinear imaging model is used to reduce the distortion effect. As a result, we will investigate other approaches to provide a more efficient solution for real-time applications. 6.ConclusionIn this paper, we propose a target search method based on salience mechanism and imaging model. This method generates a search path in which each node is a salient object with respect to its search region. When a salient object of the search path is located, search regions of the subsequent objects will decrease. The target could be found in a region that is getting smaller. The relation between salience objects and the target is used to find the target. Through these operations, target search becomes more accurate and quicker. We want to apply our method in a real application such as visual SLAM robot. We think that this method will reduce the cost of point matching for SLAM and other similar applications. At the same time, this method is also useful for scene modeling. We will continue to explore these applications. AppendicesAppendix:Power Method and Hx(ξ)A.1.Power MethodPower method is a numerical computation method that computes the maximum eigenvalue of a matrix. The pseudo code listed in Algorithm 2 gives an implementation of power method. Algorithm 2Power method max λ(M)≈xT*M*x;
A.2.Hx(ξ) and Hx(G)Because locates in the interval , we make where . We denote extrinsic parameter matrix We have . The element of matrix has the form , , . So is a function of . The element of matrix has the form , . So is a function of . When are all small increments, we have , . According to triangle inequality principal, we have . From the discussion above, we have has the same functional form as .∵nonzero eigenvalues of matrix are equal to nonzero eigenvalues of We will find that minimizes the two-norm of . As a result, we need to get to solve This equation can be converted into a semidefinite programing problem The output result is the value that we want to obtain.AcknowledgmentsThis research was supported by the National Natural Science Foundation of China (Grant No. 61272523), the National Key Project of Science and Technology of China (Grant No. 2011ZX05039-003-4), and the Fundamental Research Funds for the Central Universities. ReferencesF. Endres et al.,
“3-D mapping with an RGB-D camera,”
IEEE Trans. Rob., 30
(1), 177
–187
(2014). http://dx.doi.org/10.1109/TRO.2013.2279412 ITREAE 1552-3098 Google Scholar
M. J. Westoby et al.,
“‘Structure-from-motion’ photogrammetry: a low-cost, effective tool for geoscience applications,”
Geomorphology, 179 300
–314
(2012). http://dx.doi.org/10.1016/j.geomorph.2012.08.021 Google Scholar
R. Hartley and A. Zisserman, Multiple View Geometry in Computer Vision, Cambridge University Press, Cambridge, United Kingdom
(2003). Google Scholar
L. Itti, C. Koch and E. Niebur,
“A model of saliency-based visual attention for rapid scene analysis,”
IEEE Trans. Pattern Anal. Mach. Intell., 20
(11), 1254
–1259
(1998). http://dx.doi.org/10.1109/34.730558 Google Scholar
S. Frintrop, T. Werner and G. M. Garcia,
“Traditional saliency reloaded: a good old model in new shape,”
in Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition,
82
–90
(2015). Google Scholar
A. Borji et al.,
“Salient object detection: a benchmark,”
IEEE Trans. Image Process., 24
(12), 5706
–5722
(2015). http://dx.doi.org/10.1109/TIP.2015.2487833 IIPRE4 1057-7149 Google Scholar
X. P. Hu, L. Dempere-Marco and Y. Guang-Zhong,
“Hot spot detection based on feature space representation of visual search,”
IEEE Trans. Med. Imaging, 22
(9), 1152
–1162
(2003). http://dx.doi.org/10.1109/TMI.2003.816959 Google Scholar
A. M. Treisman and G. Gelade,
“A feature-integration theory of attention,”
Cognit. Psychol., 12
(1), 97
–136
(1980). http://dx.doi.org/10.1016/0010-0285(80)90005-5 CGPSBQ 0010-0285 Google Scholar
J. M. Wolfe,
“Visual search,”
Attention, 13
–73 University College London Press, London, United Kingdom
(1998). Google Scholar
N. Bruce, J. Tsotsos,
“Saliency based on information maximization,”
in Advances in Neural Information Processing Systems,
155
–162
(2005). Google Scholar
X. Hou, L. Zhang,
“Dynamic visual attention: searching for coding length increments,”
in Advances in Neural Information Processing Systems,
681
–688
(2009). Google Scholar
Y. Li et al.,
“Visual saliency based on conditional entropy,”
in Computer Vision–ACCV,
246
–257
(2009). Google Scholar
N. J. Butko and J. R. Movellan,
“Infomax control of eye movements,”
IEEE Trans. Auton. Ment. Dev., 2
(2), 91
–107
(2010). http://dx.doi.org/10.1109/TAMD.2010.2051029 Google Scholar
D. S. Gao, S. Han and N. Vasconcelos,
“Discriminant saliency, the detection of suspicious coincidences, and applications to visual recognition,”
IEEE Trans. Pattern Anal. Mach. Intell., 31
(6), 989
–1005
(2009). http://dx.doi.org/10.1109/TPAMI.2009.27 ITPIDJ 0162-8828 Google Scholar
L. Zhang et al.,
“SUN: a Bayesian framework for saliency using natural statistics,”
J. Vision, 8
(7), 32
–32
(2008). http://dx.doi.org/10.1167/8.7.32 1534-7362 Google Scholar
J. Harel, C. Koch, P. Perona,
“Graph-based visual saliency,”
in Advances in Neural Information Processing Systems,
545
–552
(2006). Google Scholar
S. Chikkerur et al.,
“What and where: a Bayesian inference theory of attention,”
Vision Res., 50
(22), 2233
–2247
(2010). http://dx.doi.org/10.1016/j.visres.2010.05.013 VISRAM 0042-6989 Google Scholar
Z. Y. Zhang,
“A flexible new technique for camera calibration,”
IEEE Trans. Pattern Anal. Mach. Intell., 22
(11), 1330
–1334
(2000). http://dx.doi.org/10.1109/34.888718 ITPIDJ 0162-8828 Google Scholar
J. Kannala and S. S. Brandt,
“A generic camera model and calibration method for conventional, wide-angle, and fish-eye lenses,”
IEEE Trans. Pattern Anal. Mach. Intell., 28
(8), 1335
–1340
(2006). http://dx.doi.org/10.1109/TPAMI.2006.153 ITPIDJ 0162-8828 Google Scholar
Z. Xiang, X. Dai and X. Gong,
“Noncentral catadioptric camera calibration using a generalized unified model,”
Opt. Lett., 38
(9), 1367
–1369
(2013). http://dx.doi.org/10.1364/OL.38.001367 OPLEDP 0146-9592 Google Scholar
O. Christensen and K. L. Christensen, Approximation Theory: From Taylor Polynomials to Wavelets, Springer Science & Business Media, Berlin, Germany
(2004). Google Scholar
M. M. Cheng et al.,
“Global contrast based salient region detection,”
in IEEE Conf. on Computer Vision and Pattern Recognition,
409
–416
(2011). http://dx.doi.org/10.1109/CVPR.2011.5995344 Google Scholar
M. M. Cheng et al.,
“Global contrast based salient region detection,”
IEEE Trans. Pattern Anal. Mach. Intell., 37
(3), 569
–582
(2015). http://dx.doi.org/10.1109/TPAMI.2014.2345401 ITPIDJ 0162-8828 Google Scholar
K. Mikolajczyk et al.,
“Affine covariant features,”
(2015) http://www.robots.ox.ac.uk/~vgg/research/affine/index.html November ). 2015). Google Scholar
N. Silberman et al.,
“NYU depth dataset V2,”
(2012) http://cs.nyu.edu/~silberman/datasets/nyu_depth_v2.html November 2015). Google Scholar
BiographyQi Wang received his BE and ME degrees in computer science from the Dalian University of Technology in 2009 and 2012, respectively. He is a PhD student at Dalian University of Technology. His current research interests include stereo vision, camera imaging, and image processing. Xiaopeng Hu received his ME degree in computer science from the University of Science and Technology of China and his PhD from the Imperial College London, United Kingdom. He is a professor at Dalian University of Technology. He has participated in many projects as a leader. His current research interests include machine vision, wireless communication, and 3-D reconstruction. |




