|
|
1.IntroductionIn the image alterations for the forgeries, the tampering uses compression, filtering, averaging, rotating, mosaic editing, and updownscaling. In particular, the median filtering (MF) is preferred among some forgers because it has the characteristics of nonlinear filtering based on order statistics. Furthermore, MF detection could classify the altered images with MF.1 Consequently, the prior studies2–5 emphasized that the MF detector becomes a significant forensic tool for the recovery of the processing history of a forgery image. To extract the 10 features for MF detection (MFD), Kang et al.2 obtained autoregressive (AR) coefficients as feature vectors via an AR model to analyze the median filter residual (MFR AR), which is the difference between the values of the original image and those of the median-filtered image. The authors analyzed an image’s MFR AR; it is able to suppress image content that may interfere with MFD. Yuan3 proposed the median filtering forensics (MFF) feature as a combination of five feature subsets which implied an order statistics and the gray levels to capture the local dependence artifact introduced by MF because to the two-dimensional median filter affects either the order or the quantity of the gray levels in an image region. The MFF method employed five entries for the feature set extraction. This is done by extracting a set of 44 features from an image. These sets include features such as the distribution of the block median pixel value and the distribution of the number of distinct gray levels within a window. The experimental results of the MFF in Ref. 3 can achieve comparable or better performance than the subtractive pixel adjacency matrix (SPAM)-based method4 in the case of high- and medium-quality factor JPEG postcompression and low-resolution JPEG images. However, as with Kirchner and Fridrich’s technique in Ref. 4, the performance of Yuan’s technique in Ref. 3 decreases as the JPEG quality factor is lowered or as the image size examined shrinks. The computing time to extract the MFF feature vector using the combined various entries is long, and both the performances of the SPAM-based and the MFF-based detectors degrade depending on the size of the analyzed the up- or downscaling images. Thus, there is a need to develop a more reliable method to detect MF in the case of up- and downscaling, which is more desirable in practical applications. In this paper, a new variation-based MFD method is proposed in which the feature vector is constructed using two kinds of variations between the neighboring line pairs in a digital image. One is extracted in the space domain, and the other is extracted in the frequency domain. The rest of the paper is organized as follows. Section 2 briefly presents the theoretical background of the MFR AR and the MFF method. In Sec. 3, the variation of neighboring line pairs for the extraction of the feature vector is computed, and it describes the composition of the new feature vector. The experimental results of the proposed method are shown in Sec. 4. The performance evaluation is compared with the MFR AR and the MFF, and those results are followed by some discussions. Finally, conclusions are drawn. 2.Prior Median Filtering Detectors2.1.Feature Set for Median Filtering DetectionThe median pixel values obtained from overlapping filter windows are related to one another as the overlapping windows share several pixels in common. According to this fact, most state-of-the-art MF detectors2–5 for the feature vector used different lengths and the employed some methods for the extraction of the feature set. To extend the length of the feature vector to increase the classification ratio between the altered and unaltered images, the extraction time of the feature set and the training-testing time both take longer. In Ref. 5, kernel principal component analysis is used to reduce the length of the feature vector, therefore, additional computational time is required. Most MF detectors employ several conventional extraction methods that are processed in the space/frequency domain or use the statistical theory. 2.2.Median Filter Residual MethodKang et al.2 used the 10-dimensional (10-D) feature vector, which was extracted from the AR coefficients of the difference in the images between the original and its MF image. They computed an MFR. In Ref. 2, the authors attempted to reduce interference from an image’s edge content and the block artifacts from JPEG compression. They proposed gathering detection features from the MFR. The image between the original and its MF image is used to construct the AR model. The difference is referred to as the MFR, which is formally defined as where is a pixel coordinate and is an MF window size.Subsequently, AR coefficients are computed as where and mean the row and column directions, respectively, and is the AR order number, , and is the maximum order number. In Eq. (4), the AR coefficients in both directions are averaged to obtain a single, one-dimensional AR model.Again, the AR coefficients are for the difference in images according to the following: where and are the prediction errors6 in the row direction and column direction, respectively, and is a surrounding range of .2.3.Median Filtering Forensics MethodYuan3 proposed detecting an MF by measuring the relationships among the pixels within a window from an image. The author believed that in a median-filtered image, the gray level of the block center should occur more frequently in the block after MF. For this reason, the sets include features such as the distribution of the block median pixel value and the distribution of the number of distinct gray levels within a window. Moreover, the author proposed a median filter detector that collects blockwise the MFF, which is statistically based on the pixel values and their distribution on the block. A set of five features in the MFF is extracted from a nonoverlapping block:
A direct combination of these feature subsets results in a 44-dimensional feature vector (note that the and the are equivalent) which is used for MFF.Different features of the MFF are then combined heuristically to produce a new index , and MFD is then obtained by simply thresholding A binary decision is then made according to the index to determine whether the image has undergone MF.3.Proposed Median Filtering Detection Algorithm3.1.Variation of Neighboring Line PairsIn an image , the intensity gradient between the neighboring line pairs (the row and column directions) are defined as and , respectively, as follows: where and are row and column directions, respectively, , mean, and desc are feature dimension length, average, and descending order, respectively. This averages the in both directions to obtain a single dimension.Furthermore, the row and column differences of the Fourier transform (FT) coefficient () between the neighboring line pairs are defined as and , respectively, in the same manner of Eq. (8)–(10), to as follows: Also, as in Eq. (10), it averages the in both directions to obtain a single dimension.3.2.Feature Vector CompositionThe feature set for the proposed variation-based MFD method is composed of 19-dimensions (19-D). The in is set to be 1 to 9, which are the nine most significant values by descending order of , and the in is set to be 1 to 10, the 10 most significant values by descending order of . Both s are defined as the feature vector length based the variations of and . The first 9-dimensional (9-D) part is related to the variation that is the differences between the intensity values between neighboring line pairs. The nature of the feature and length is similar to the MFF OBC3 according to the space domain processing. The second 10-D part is related to the variations that are the differences between the coefficient values of FT between neighboring line pairs. The nature of the feature and length is similar to the MFR AR2 according to the frequency domain processing. The proposed complete MFD technique can be summarized as follows:
4.Experimental ResultsIn this section, the experimental methodology used in the experiments is described, and then compared to the experimental results of the proposed variation-based MF detector to the MFR AR and the MFF methods to verify the effectiveness of the proposed method. The MFR AR which has a very short 10-D feature vector and the MFF have good performances in the existing MF detectors, so they are the best to compare. 4.1.Experimental MethodologySVM training and testing was performed by inputting the constructed 19-D feature vector to an SVM classifier for the training of the MF classification. -SVM7 with Gaussian kernel is employed as the classifier Moreover, it trained in an SVM classifier with fourfold cross-validation in conjunction with a grid search for the best parameters of and in the multiplicative grid The searching step size of is 0.25, and then those parameters are used to get the classifier model on the training set.The experiments prepared the following image database:
This results in the image database and, where necessary, the images were converted to 8-bit grayscale images and used in the experiments. For the effective measurement of the proposed method in the experiment, four kinds of test items, area under curve (AUC), the classification ratio, the minimal average decision error (), and at ( and denote the true-positive and false-positive rates, respectively). Also, the classified rate of the experimental AUC results is interpreted using the traditional academic point system. The definition of AUC grade is described in Ref. 11 BOWS2 10,000 images, UCID 1388 images, and SAM 5150 images are used for MFD, and the test image types are prepared as ORI (unaltered), MF3 (median window size: ), MF5 (median window size: ), MF35 (“35” denotes the MF3 and MF5) composed of the randomly selected images (each 5000 in the MF3 and MF5 of BOWS2, each 694 in the MF3 and MF5 of UCID, and each 2575 in the MF3 and MF5 of SAM, respectively), JPEG (), downscaling (0.6), upscaling (1.5), and upscaling (2.0), respectively.Subsequently, the trained classifier model is used to perform the classification on the testing set. Among the total of 16,538 images, 10,000 images are selected randomly in training, and the other 6538 images are for testing. Before an SVM classifier is trained for the MFD, it prepared the (,) for the positive data, and the negative data are three groups, , , and , as follows: 4.2.Experimental ResultsThe proposed method compared with existing works: the MFR AR2 and the MFF methods.3 For the proposed method, the experiments were conducted using the MATLAB® (R2015a) tools on PC environment (the 64-bit version of Windows 7, Intel® core™ i7-5960X CPU @ 3.00 GHz and DDR4 32 GB memory). The extracted feature set distribution of variety images from the proposed variation-based MF detector is shown in Fig. 1. The JPEG () is very similar to the original image, but the rest of the images are quite different from each other. Figures 2 and 3 show the variations of the gradient difference and the coefficient difference of the neighboring line pairs by Eqs. (10) and (13), respectively. Fig. 1Distribution of the features extracted from different types of sample images: the group images (a) , (b) , (c) and .  In Fig. 4, receiver operating characteristic (ROC) curves show each performance of versus the test image groups , , and , on the MFR AR method. In this part, the MFR AR method shows the best performance of the MFD against the UP, while, the performances of the DN, JPG, and ORI are relatively lower. Fig. 4ROC curves of the MFR AR method. (a) MF3 versus test images of group , (b) MF5 versus test images of group , (c) MF35 versus test images of group , (d) MF3 versus test images of group , (e) MF5 versus test images of group , (f) MF35 versus test images of group , (g) MF3 versus test images of group , (h) MF5 versus test images of group , and (i) MF35 versus test images of group .  In Fig. 5, ROC curves show each performance on the MFF method. In this part, the MFF method shows the best performance of the MFD in the JPEG and DN, but the performance is relatively low in UP. Fig. 5ROC curves of the MFF method. (a) MF3 versus test images of group , (b) MF5 versus test images of group , (c) MF35 versus test images of group , (d) MF3 versus test images of group , (e) MF5 versus test images of group , (f) MF35 versus test images of group , (g) MF3 versus test images of group , (h) MF5 versus test images of group , and (i) MF35 versus test images of group . 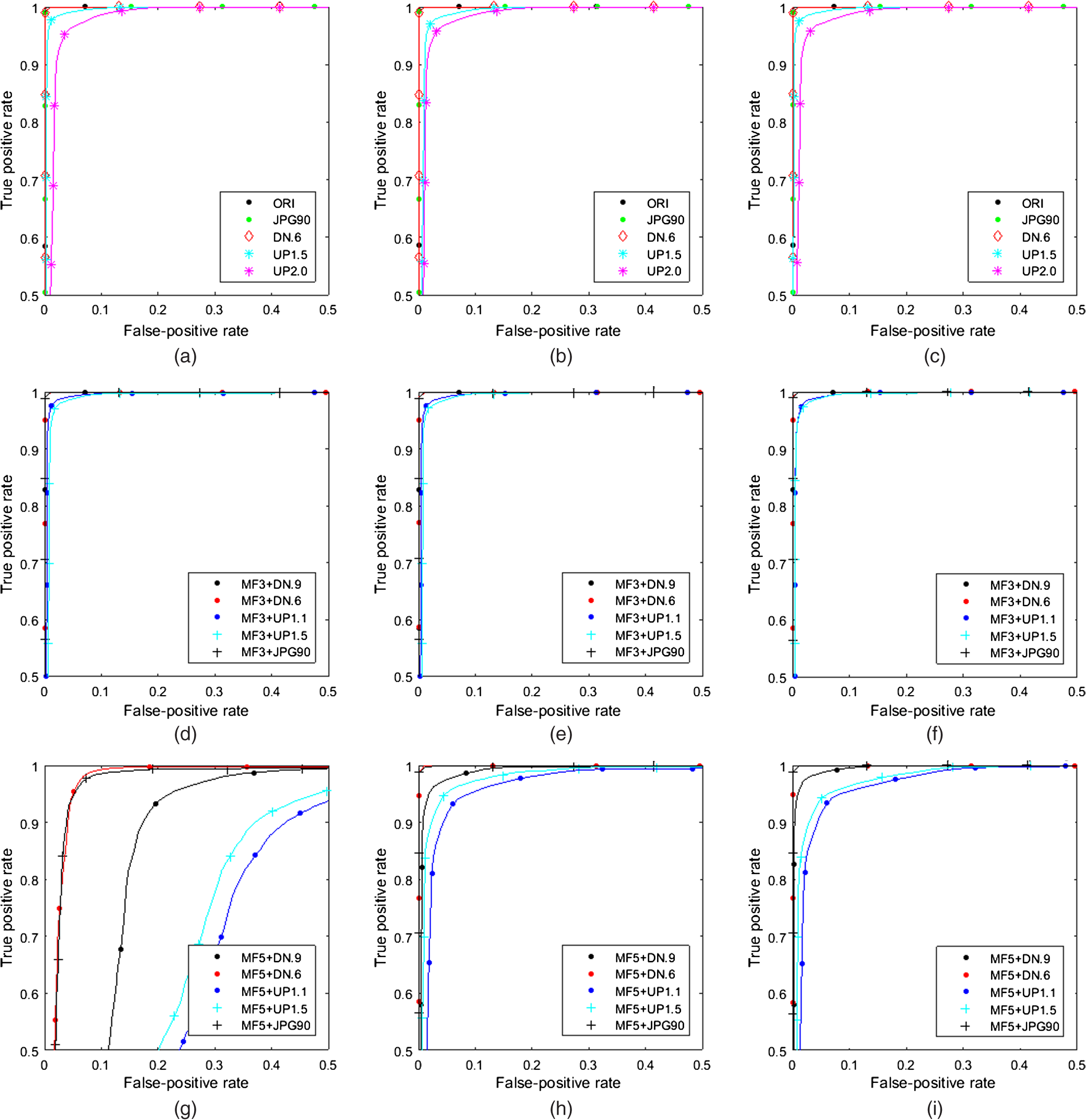 In Fig. 6, the proposed method exhibits excellent performance on all versus almost test image groups, except for MF5 versus ORI. It conducted performance evaluation and theoretical analysis for the MFD in the various altered image types. Fig. 6ROC curves of the proposed variation-based MFD method. (a) MF3 versus test images of group , (b) MF5 versus test images of group , (c) MF35 versus test images of group , (d) MF3 versus test images of group , (e) MF5 versus test images of group , (f) MF35 versus test images of group , (g) MF3 versus test images of group , (h) MF5 versus test images of group , and (i) MF35 versus test images of group . 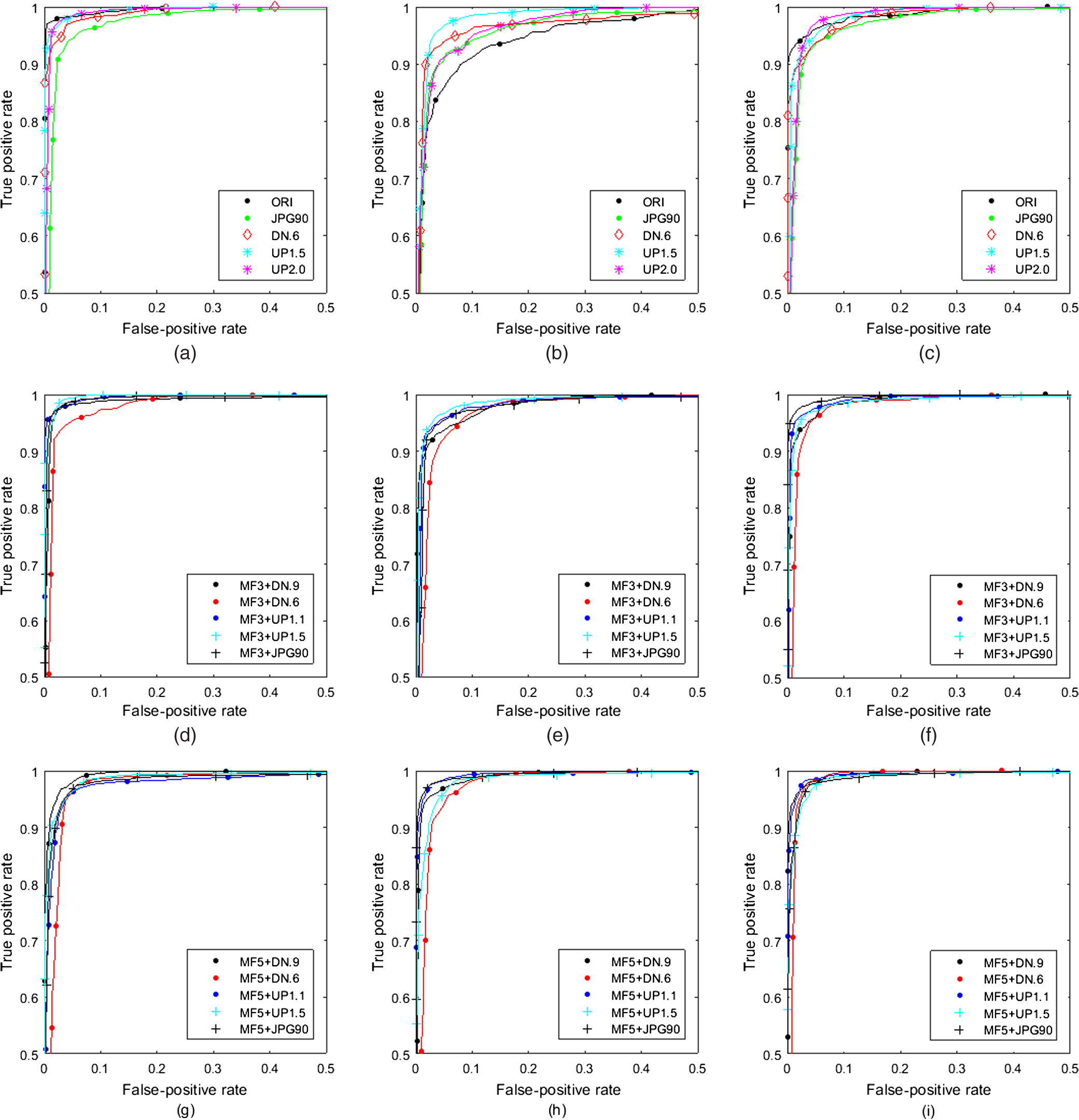 Table 1 shows experimental results of and the test image groups , , and , which presented as (a), (b), and (c), respectively. In this table, there are four kinds of test terms: AUC, the classification ratio, , and at . As a result, the AUC and the classification ratio are both above 0.9. ranges from 0.003 to 0.027, and at ranges from 0.965 to 0.996. Table 1Performance comparison between the MFR AR, MFF, and the proposed method. (The best result for each training–testing pair is displayed in bold type as a whole.) No. (experimental result item) 1: AUC, 2: classification ratio, 3: Pe, 4: PTP at PFP=0.01.
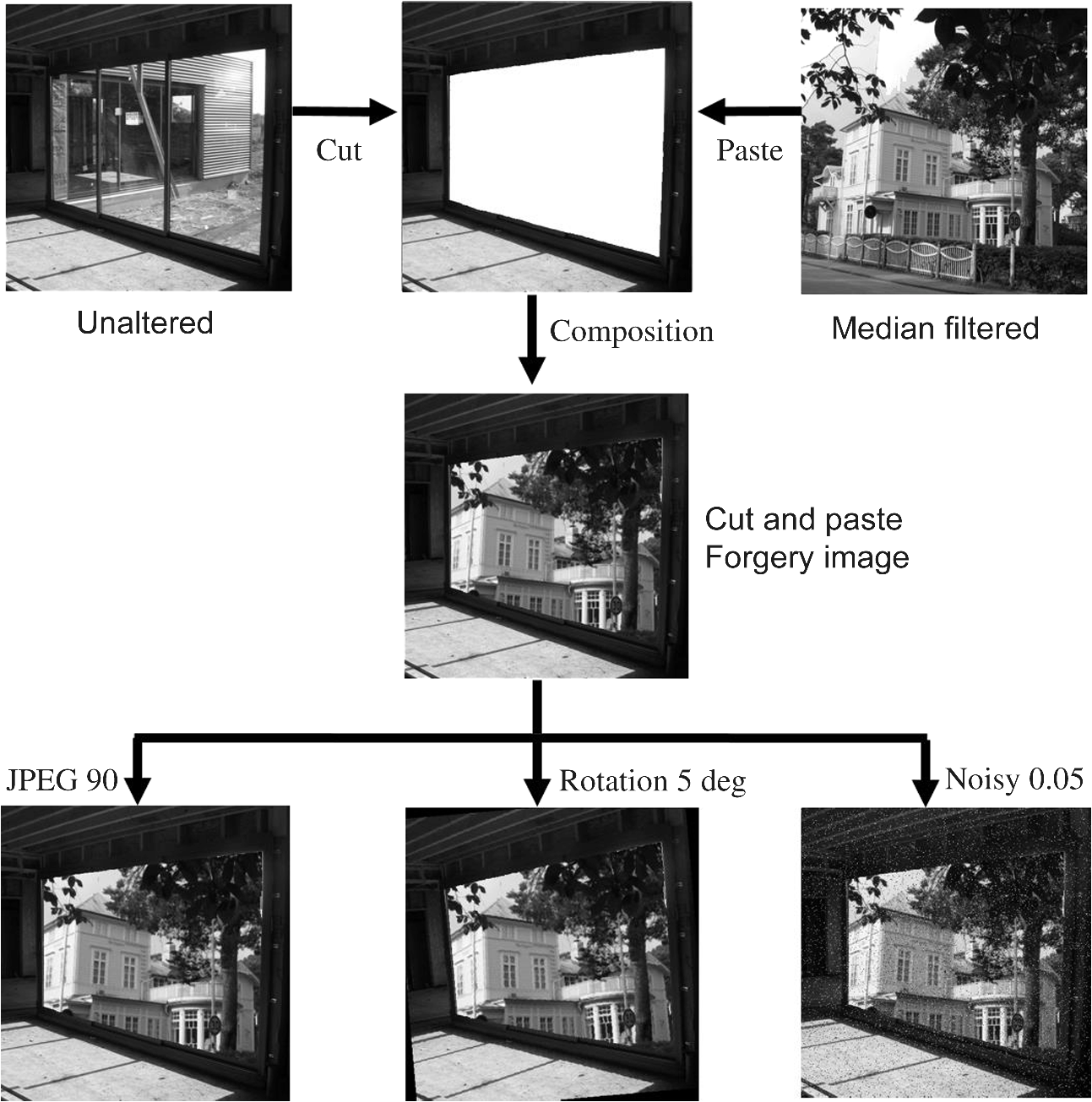
Moreover, the ROC curves of the proposed method for the many types of the test image are relatively closer to each other, which indicates the more consistent classification performance of the proposed method. Overall, the performance is excellent at unaltered (original), JPEG () compression, downscaling (0.6), and upscaling (1.5 and 2.0) images on the MF3, the MF5, and the MF35 detections. However, in the proposed variation-based MFD methods, despite the 19-D short length of the feature vector, the performance results of the AUCs approached 1. Thus, it is confirmed that the grade evaluation of the proposed algorithm is rated as “Excellent (A).” [The classified rate of the experimental AUC results is interpreted using the traditional academic point system11 (June 2016).] In this evaluation, it uses the terms of general interpretation AUC for each training–testing pair. Subsequently, the testing of the MF to detect low-resolution images will be examined. A small image window size is a requirement for detecting forgeries in a median-filtered image or modified JPEG pre- or/and postcompression. An example of a cut-and-paste forgery image is shown in Fig. 7. An unaltered image (window) is cut, and a median-filtered image (house) is pasted onto the cut area (white region) of the unaltered image (those unaltered images come from the BOWS2 database), forming a composite image, which was then JPEG postcompressed using a quality factor of 90, rotated counterclockwise by 5 deg and added salt and pepper noise by 0.05 density. Figures 8Fig. 9–10 show the detection blocks of MF with the MFR AR, the MFF, and the proposed method, respectively. The detected blocks that are median-filtered (the true positives) are marked in red, and the remaining blocks are marked in blue (the false alarms). (The color version of the paper is available online.) In Figs. 8Fig. 9–10, the left column (a, c, e, and g) is examined in a block size, and the right column (b, d, f, and h) is examined in a block size. The first row (a and b) shows the detection results in MF3 versus unaltered images, the second row (c and d) shows the detection results in MF3 + JPG90 versus JPG90 images, the third row (e and f) shows the detection results in MF3 versus unaltered to rotated images, and the last row (g and h) shows the detection results in MF3 versus unaltered to noisy images. In Fig. 8, the MFR AR method does not perform well for a size image, and it performs only slightly better for MF3 versus unaltered images on a size image. In Fig. 9, the MFF method performed well for MF3 versus unaltered images and rotated one for both and size images. Meanwhile, the corresponding forensic detection does not provide good results in JPEG postcompression. In Fig. 10, the MFD of the proposed method with a 19-D feature vector is supreme for MF3 versus unaltered images, under JPEG postcompression, and its rotated and noisy one for both and size images, respectively. 5.ConclusionsThis paper proposed a variation-based MFD method, the constructed feature vector that was composed of two kinds of variations from the space and the frequency domain in an image. The extracted one is computed on the gradient differences between the neighboring line pairs, and the other is computed on the FT coefficient differences. All of that increases the experimental results in the MFD. To the best of our knowledge, this is the first complete solution for the variation between the neighboring line pairs of a digital image. So this will serve as additional research content for MFD. Future work should consider a performance evaluation of the smaller size as an altered image. Finally, the proposed variation-based method can be applied to solve different forensic problems, such as the previous MFD methods. AcknowledgmentsThis work has been supported by the research grant (322386) of Chosun University, Republic of Korea, in 2015. ReferencesK. H. Rhee,
“Median filtering detection using variation of neighboring line pairs for image forensic,”
in IEEE 5th Int. Conf. on Consumer Electronics-Berlin (ICCE-Berlin),
103
–107
(2015). http://dx.doi.org/10.1109/ICCE-Berlin.2015.7391206 Google Scholar
X. Kang et al.,
“Robust median filtering forensics using an autoregressive model,”
IEEE Trans. Inf. Forensics Secur., 8
(9), 1456
–1468
(2013). http://dx.doi.org/10.1109/TIFS.2013.2273394 Google Scholar
H. Yuan,
“Blind forensics of median filtering in digital images,”
IEEE Trans. Inf. Forensics Secur., 6
(4), 1335
–1345
(2011). http://dx.doi.org/10.1109/TIFS.2011.2161761 Google Scholar
T. Pevný, P. Bas and J. Fridrich,
“Steganalysis by subtractive pixel adjacency matrix,”
IEEE Trans. Inf. Forensics Secur., 5
(2), 215
–224
(2010). http://dx.doi.org/10.1109/TIFS.2010.2045842 Google Scholar
Y. Zhang et al.,
“Revealing the traces of median filtering using high-order local ternary patterns,”
Signal Process. Lett. IEEE, 21
(3), 275
–279
(2014). http://dx.doi.org/10.1109/LSP.2013.2295858 Google Scholar
S. M. Kay, Modern Spectral Estimation: Theory and Application, Prentice-Hall, Englewood Cliffs, New Jersey
(1998). Google Scholar
C. C. Chang and C. J. Lin,
“LIBSVM: a library for support vector machines,”
(2016) https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/ April ). 2016). Google Scholar
G. Schaefer and M. Stich,
“UCID—an uncompressed color image database,”
Proc. SPIE, 5307 472
–480
(2004). http://dx.doi.org/10.1117/12.525375 PSISDG 0277-786X Google Scholar
Q. Liu and Z. Chen,
“Seam-carving image database,”
(2014) http://www.shsu.edu/~qxl005/New/Downloads/index.html April 2016). Google Scholar
T. G. Tape,
“The area under an ROC Curve,”
(2016) http://gim.unmc.edu/dxtests/roc3.htm April ). 2016). Google Scholar
BiographyKang Hyeon Rhee is with the Department of Electronics Engineering, Chosun University, Gwangju, Republic of Korea. His current research interests include embedded system design related to multimedia fingerprinting/forensics. He is on the Committee of the LSI Design Contest in Okinawa, Japan. He is also the recipient of awards such as the Haedong Prize from the Haedong Science and Culture Juridical Foundation, Korea, which he received in 2002 and 2009. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||