|
|
1.IntroductionAs a technology used to extract a region of interest automatically or semiautomatically, image segmentation is a key step in image analysis and understanding studies.1 It is used for object model representation, parameter extraction, object recognition, and for video encoding of objects in MPEG4.2 Until now, there have been lots of segmentation methods for all kinds of purposes, such as organ extraction in medical applications3 and object detection in the remote sensing systems.4 However, they are all only used for some specific purposes, and it is difficult to generalize them to any image segmentation tasks. Consequently, a uniform segmentation framework is required for researchers and developers.5 Generally, image segmentation is implemented based on similarity and dissimilarity among subregion features,6 such as color, intensity, statistical characteristics, and specific shape. However, real images contain a large amount of inhomogeneous subregions and are unavoidably affected by noise. On the one hand, inhomogeneous subregions may form weak edges or deteriorate the similarity of the subregion, i.e., intensity uniformity. On the other hand, since noise causes pseudo-edges and weakens the significant difference among subregions,7 the nonrobustness of the subregion characteristics is aggravated. Active contour models for image segmentation are popular algorithms for dividing an image into foreground and background. The basic idea is a deformable curve, which conforms to various shapes of objects. Combining the piecewise smoothing with the statistical properties of the noise, Chan and Vese proposed the region-based active contour model (CV model).8 In this model, the object and background regions are represented as the mean of subregions respectively. Thus, it is insensitive to noise and helpful for enhancing the computational efficiency of the Mumford–Shah model.9 The results of segmentation using the CV model are unsatisfactory for real images. The reason is that in-homogeneity reduces significant differences of the mean of subregions. In order to improve the segmentation performance, Tsai and Yezzi proposed a piecewise smooth (PS) model10 by approximating pixels of subregion into a function. Compared to the CV model, the PS model is insensitive to inhomogeneous subregions, but it is difficult to apply it in practice due to the expensive computational cost. Therefore, Li and Kao proposed a local binary fitting model,11 which employs the Gauss kernel function to approximate the neighborhood pixels of the active contour. Peng and Liu proposed an active contour model driven by normalized local image fitting energy.12 Although the above models have strong locating capabilities, the results of segmentation rely on the assumption of approximation function and the initial curve. In order to overcome these shortcomings, a large number of research works were investigated. To strengthen the robustness of the initial curve, Jiang and Feng proposed a segmentation model based on improved level set and region growth, which takes the statistical information of an object as seed.13 Based on regional-similarity and the level set, Kong and Wang proposed the segmentation model to improve the hypothesis of approximation function model.14 Although region-based active contour segmentation models are generally robust to noise, they are valid only for images with homogeneous region given the number of subregions. According to the relationship between contour and edge, Li et al. proposed an edge-based active contour segmentation model.15 Unfortunately, it is sensitive to noise and inhomogeneous subregions. To cope with this, images are often smoothed with a Gaussian filter. However, a Gaussian filter is an isotropic point diffusion that crosses the boundaries of subregions and leads to the level set curve converging at the neighbor of object contours. Furthermore, a Gaussian filter with large standard variance may seriously blur boundaries formed by weak edges. This leads to the overconvergence of curves, and conversely the curves will be premature. It is difficult to adaptively choose standard variance for different regions in an image.16 By incorporating prior object-shape information into the initial evolving curve, Yeo and Xie improved the accuracy of segmentation for specific shape regions.17 Under- and over-segmentation phenomenon exist when traditional active contour models are applied to real images due to inhomogeneous subregions and weak edges. In order to smooth the inhomogeneous subregions and preserve edges, we propose the smoothing conditions for image segmentation: (1) isotropic smoothing inside the subregions and (2) anisotropic smoothing along the edge. Unfortunately, the aforementioned conditions are incompatible. Inspired by total variation,18 we construct an edge-preserving smoothing model, which is a compromise of the above conditions. Further, due to the location of edges, a fixed edge-preserving parameter is not a reasonable trade-off between edge-preserving and subregion smoothing. It will cause blurred-edges and residual nonuniformity in the smoothing component. To solve this problem, we investigate the two-clustering algorithm of center pixel and four neighbors to adjust the edge-preserving parameter adaptively. Fixed-point iteration is employed to compute the smoothing component. While the number of iteration is high, the smoothing component converges to the mean of the image, and the difference between the feature of an object and that of the surrounding region is not significant. To avoid these, we construct a smoothing convergence condition according to the confidence level of segmentation subregions on different smoothing components. The experimental results show that this segmentation model is insensitive to noise and inhomogeneous-regions. The outline of the paper is as follows. In the next section, two conditions on image piecewise smoothing are proposed to construct an edge-preserving smoothing model, and the clustering algorithm is employed to learn the edge-preserving parameter. In Sec. 3, a new segmentation model for the edge-preserving smoothing component is proposed. The proposed image segmentation model is implemented in Sec. 4. The experimental results are given in Sec. 5. Finally, the conclusion is given in Sec. 6. 2.Proposed Edge-Preserving ModelThe active contour model for image segmentation is curve evolution implementation based on the Mumford–Shah model.9 It is formulated as the following minimization problem: where is the segmentation curve, is a given image, is a piecewise smoothing component of an image and contains homogeneous subregions and significant differences among subregions. The piecewise smoothing component is a solution of the following problem: To analyze the diffusibility performance for the smoothing function , the function is decomposed using the local image structures, i.e., the tangent and normal directions. The diffusibility performances along the tangent and normal directions are denoted by and , respectively:2.1.Edge-Preserving SmoothingIn order to smooth subregions and preserve edges for real images, the diffusibility performance of the function along the tangent and normal directions should satisfy the following two conditions:
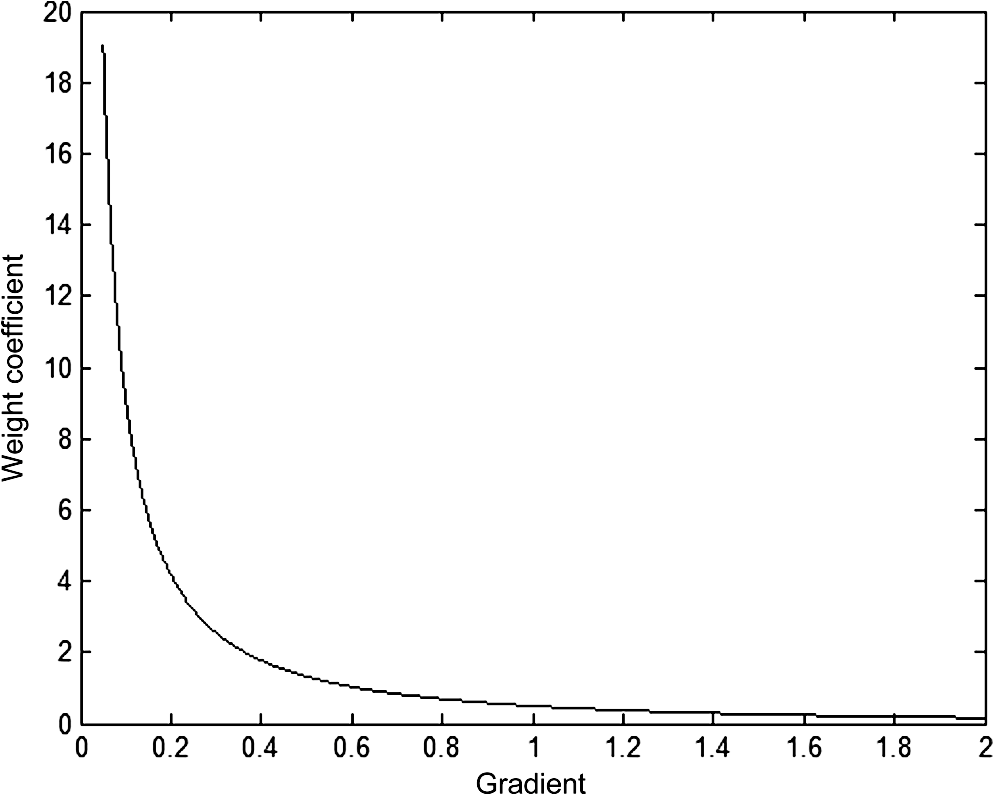
In the Mumford–Shah model,9 the -norm of the gradient is a smoothing function for segmentation. The diffusibility performances of this function along the tangent and normal directions are the same, i.e., . The diffusion actions in the normal direction cross the edge; thus, this function cannot satisfy the second condition. To preserve the edge, Chan et al.18 proposed the total variation that the -norm of the gradient replaces the -norm. The performance along the normal direction is zero. It does not satisfy the first condition, which leads to a pseudoedge in the smoothing subregions. Unfortunately, the above two conditions are incompatible. Compared with the piecewise smoothing functions of the Mumford–Shah model9 and total variation,18 we design an edge-preserving smoothing function for image segmentation. The diffusibility performance in the tangent and normal directions are as follows: Inside the subregion where gradients are low, , ; at the edge where gradients are strong, , and (see Fig. 1). It is a compromise of two conditions on edge-preserving smoothing. This function preserves the edge and smooths the inhomogeneous subregion. Therefore, the edge-preserving smoothing model is given asFig. 1The diffusibility performance of this function. The solid and dash dot curve denote the diffusibility in the tangent and normal direction, respectively.  This problem allows for a unique solution characterized by the Euler–Lagrange equation: To compute the smoothing component, we use a semi-implicit finite difference scheme. Let a set is four neighbors region of the center pixel (), and is a member of set , the approximation of Eq. (9) can be simply written as where is the edge-preserving parameter, in other words, it is the weight coefficient of the center pixel. The is the weight coefficient of the neighbor pixel , the relationship between and the gradient is shown in Fig. 2.2.2.Adaptive Edge-Preserving SmoothingIn traditional edge-preserving smoothing algorithms (i.e., TV18), the edge-preserving parameter in Eq. (10) often is fixed by an artificial setting. If , then . The smoothing component contains the redundancy of inhomogeneous subregion, which causes the level set converge to local optima. If , the approximates the weighted-mean of four neighborhood pixels. The edge of the smoothing component is blurred, the segmentation-curve is overconvergence. Above all, the fixed parameter cannot weigh up the edge-preserving and subregion smoothing according to local information of an image. To solve the above problem, we analyze the two-clustering of the center pixel and four neighbors based on their possible spatial relationship.
The two-clustering of the center pixel and its four neighbors are shown in Fig. 3. Observed from Fig. 3, the edge-preserving parameter is set as the medium of the weight coefficients of the center pixel and its four-neighbor: where is the constant, which normalizes parameter .Fig. 3The two-clustering of the center pixel and its four neighbors, the white and black circles denote object and background, respectively. (a) All pixels in the object region, (b) one of the four neighbor pixels locates in background and others in object region, and (c) two of the four neighbor pixels locate in background and others in object region. 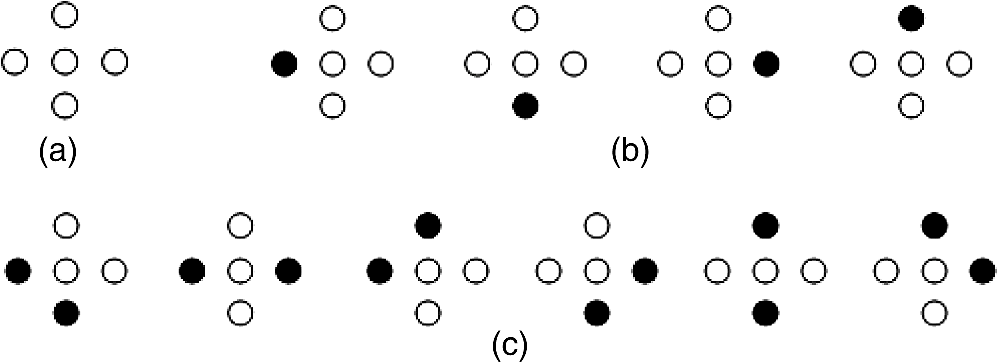 3.Segmentation ModelIn terms of the analysis in Sec. 2, the segmentation model on the smoothing component is proposed as the following minimization problem: During image segmentation, the curve may have a topological deformation (split or merge). To cope with this problem, active contours based on the level set are applied into image segmentation. The basic idea is to represent contours as the level set of an implicit function , i.e., . The inside-region denotes and outside-region is . To simplify, both regions are approximated by the Heaviside function . The curve is represented as the Dirac measure , which is the derivative of , where and are defined as, respectively, However, cannot satisfy the regularity condition , the penalty term is introduced15Since the circumference and the area of the closed curve become smaller, the optimal segmentation curve is represented as where and are the weight of the circumference and area of curve, respectively, and is the edge indicator function of the smoothing componentIf the level set curve locates in where the gradients are low, the edge indicator function is almost the maximum of the entire image. Otherwise, the edge indicator function is the minimum, and the level set curve convergence to the boundary. Consequently, we incorporate the edge-preserving smoothing model into the above segmentation model, and construct the energy function of the edge-preserving smoothing segmentation model. To minimize the function , we denote the Gateaux derivative19 of the function as . By calculating variations, the Gateaux derivative of the function in Eq. (18) can be written as where is the Laplacican operator. Therefore, satisfies the Euler–Lagrange equation. By introducing an artificial temporal variable , we use the steepest descent process to get minimization of the function , whose gradient flow is4.ImplementationIn Eq. (20), the Dirac measure is noncontinuous. When calculating the level set, take continuous () instead of In this paper, the is approximated by the forward difference, and the is approximated by the central difference. The approximation of Eq. (20) for the smoothing component can be simply written as where, is the time step, and is edge indicator function of the smoothing component . is calculated by the fixed-point iteration algorithm For Eq. (23), the smoothing component converges to the mean of the initial image without constraint conditions, which leads to the difference between the features of the object and the surrounding region not being significant. To avoid this phenomenon, we present the confidence level of segmented subregions on two adjacent iterations of the smoothing component, which is defined as following: Here the set and represent the segmented subregions for the smoothing component and , respectively. When the confidence level satisfies the following condition, the smooth is terminated: where is the threshold of the regional confidence level.The steps of image segmentation (output) {Initial: and } N is the iterative number of image smoothing Begin N:= 0; Repeat Computing the weight coefficient of smoothing component uses: Computing the edge-preserving parameter : Computing the smoothing component uses: Computing the edge indicator function of the smoothing component uses: Segmentation of the smoothing component uses: Eq. (22) Until The convergence condition: Eq. (25) Output: the result of segmentation. End 5.Experimental Results5.1.Implementation DetailsThe experiments are conducted using VC 6.0 on a PC with Intel-Core i5 CPU @ 3.40 GHz and 4 GB of RAM without any particular code optimization. During the implementation of the proposed model, we used the parameters , , and time step for all experiments. Here, we propose the following functions as the initial function . Let be all the points on the boundaries of which is a subset in the image domain . Then, the initial function is defined as where is a constant. We suggest to choose larger than , where is the width in the definition of the regularized Dirac function in Eq. (21).In this paper, we use three universally agreed on, standard, and easy-to-understand measures for evaluating a segmentation model, those are precision, recall, and F-measure. The first two evaluation metrics are based on the overlapping area between ground truth and segmentation regions. Usually, neither precision nor recall can comprehensively evaluate the quality of segmentation. So the F-measure is proposed as a harmonic mean of them. For a segmentation object region, we can convert it to a binary mask and compute precision and recall by comparing with ground-truth 5.2.DiscussionThe image is smoothed using the edge-preserving smoothing model in the proposed model, so the segmentation performance depends on the parameter in Eq. (12). To analyze the relationship between and the scores of image segmentation (precision, recall, and F-measure), a -pixel image with grass and sand in the Berkeley segmentation database is smoothed with different parameter , and the results of segmentation are shown in Fig. 4. The initial curve and ground truth are represented as a red rectangle and yellow curve, respectively, in the top left-hand corner subimage of Fig. 4. Fig. 4The results of segmentation, edge indicator functions, and smoothing components with different parameter . (a) The flowerbed, (b) the edge indicator function, and (c) the cartoon component. Row 1: original images and initial curves, rows 2 to 5: the results of segmentation, edge indicator function, and smoothing component using 0.005, 0.05, 0.2, 0.25, and 0.5, respectively.  As illustrated in the second row, the subregion pixels close to constant and the edge are blurred by this smoothing algorithm with . The blurred edge leads to the over-convergence of the level set, which results in parts of the object region pixels being mistaken as the background. Thus, the recall is low at 0.862. The precision and the F-measure are 0.995 and 0.915, respectively. As illustrated in the last row, when , the smoothing component contains remnants of an inhomogeneous subregion, which leads to the level set convergence at the local optimum. The precision is low, and the F-measure is 0.848. Figure 5 shows CPU times and scores of the segmentation on Fig. 4 using this model with different parameters . While is smaller, the precision, recall, and F-measure of the segmentation are lower and the CPU time is shorter. Fig. 5The CPU time (in seconds) and score of segmentation in Fig. 4. (a) The CPU time of the segmentation using the different parameter . (b) The red, green, and blue curves show the F-measure, precision, and recall of the segmentation the different parameter using the different parameter , respectively.  If is large, the remnants inhomogeneous subregion leads to the level set’s fast convergence at the local optimum. When , this model preserves the edge and smooths the inhomogeneous subregion. The maximum difference of the F-measure is 0.005, e.g., the F-measures of the segmentation with and 0.18 are 0.98 and 0.975, respectively. In this model, the smooth components converge to the mean of the image without constrained conditions, which leads to the difference between the feature of the object and that of the surrounding region not being significant. To avoid this, we use the threshold of segmented subregions confidence level. To validate how the threshold affects the segmentation performance, a -pixel potted-tree image of the Berkeley segmentation database, in which some subregions are inhomogeneous (crown of the tree), is segmented with different thresholds. The segmentation results are shown in Fig. 6. The initial curve and the ground truth, represented as a red rectangle and blue curve, respectively, are shown in Fig. 6(a). The smoothing component retains an inhomogeneous subregion by this smoothing algorithm using the threshold , which leads to parts of background region pixels being mistaken as the object [shown in Fig. 6(b)]. The precision of segmentation is 0.937, and the F-Measure is 0.959. When , the weak edge is smoothed [see the inside circle in Fig. 6(f)] and the computation time is longer. The F-measure, recall, and precision are 0.978, 0.961, and 0.997. The CPU time and score of segmentation using this model with the different threshold are shown in Fig. 7. As shown in Fig. 7, when the threshold increases, the computation time using this model is longer. If the threshold closes to one, the F-measures of segmentation descend. Fig. 6The results of segmentation with different thresholds. (a) Initial curve and the ground truth and (b)–(f) the results of segmentation using different thresholds 0.95, 0.96, 0.97, 0.98, and 0.99, respectively.  Fig. 7The CPU time and score of segmentation in Fig. 6. (a) The CPU time of the segmentation using the different threshold . (b) The red, green, and blue curves show the F-measure, precision, and recall of segmentation with the different threshold , respectively.  The parameter is the constant that normalizes parameter and parameter is the threshold of the regional confidence level. In order to preserve the edge and smooth the inhomogeneous subregion, we suggest to choose and . 5.3.Segmentation Algorithm ComparisonsTo test segmentation performance using the proposed method on real images with slightly inhomogeneous subregions, the experiments are carried on to compare with the Li’s model,15 TB model,20 and the CV model.8 The choice of these algorithms is motivated by the following reasons: these four algorithms all employ the level set. Li’s model and TB model exploited the edge feature; the image is preprocessed by the Gaussian filter and the classical TV, respectively. In the TB model, the TV smoothing and the smoothing-component segmentation are individual steps. The number of iterations was not taken into consideration. The CV model uses the regional characteristics of the subregion to represent the object as the mean of the subregion. The different sizes of images are segmented, which are from the International web and the Berkeley segmentation database. The partial results are shown is shown in Fig. 8. The effects of the four algorithms on the homogeneous image are almost similar, such as Fig. 8(a). For the image with weak edges [i.e., Fig. 8(b)], the results of segmentation using the proposed method and TB model are better than those of the other two models. Segmentation performance using the CV model is poor for inhomogeneous subregions, e.g., Fig. 8(c), and the F-measure is 0.812. This is the reason that the intensity mean of a subregion indicates the region. Fig. 8Comparison of the proposed method with Li’s model13 and the TB model,20 and the CV model8 on real images. (a) The lotus, (b) the eagles, and (b) the butterfly. Row 1: original images and initial curves, row 2: segmentation results of the CV, row 3: the segmentation results of Li’s model, row 4: segmentation results of the TB model, row 5: the segmentation results of the proposed model, and row 6: the ground truth.  However, the effect of the proposed method for images with a seriously inhomogeneous region, such as the images in Fig. 9, is better than that of the other three models. Fig. 9Comparison of the proposed method with Li’s models13 and the CV model8 on real images with serious in-homogeneity. (a) The blossom, (b) the viburnum, and (c) the cycas. Row 1: original images and initial curves, row 2: segmentation results of the CV model, row 3: the segmentation results of Li’s model, row 4: segmentation results of the TB model, row 5: the segmentation results of the proposed model, and row 6: the ground truth.  The objector region is divided into many subregions using the CV model,8 which is that the object region contains many subregions with different intensities. The Li’s model13 avoids oversegmentation, but the segmentation curve is far away from the true boundaries where gradients are low. The positional accuracy using the TB model20 is higher than that of Li’s model, there is oversegmentation, as shown in Fig. 9(c). The segmentation curve using the proposed method cannot locate at the object boundaries with weak edges [i.e., Fig. 9(a)]. For the images in Figs. 8 and 9, the CPU time and scores of segmentation are given in Table 1. Table 1The comparison of CPU time and scores of segmentation in Figs. 8 and 9.
Compared to the effect of Li’s model, the TB model and the CV model on real images with inhomogeneous subregions and weak edges, the effect of the proposed method is better. Nevertheless, the computation time using the proposed method is costly, which is the reason that this method uses iteration smoothing to deal with the inhomogeneous subregion. However, Li’s model uses the Gaussian smoothing only one time, and the CV model does not smooth the image. For images of the same size, the iterative number mainly depends on the region’s inhomogeneous degree, such as for images in Figs. 8(b) and 9(a), the CPU time using the proposed method is 8.985 and 11.66 s, respectively. To test the proposed method’s robustness against noise, segmented experiments on a degraded image with additive white noise are conducted and compared with Li’s model,15 the TB model,20 and the CV model.8 Partial results are shown in Fig. 10. With the PSNR decreasing, the isotropic diffusion in Li’s model blurs the object contour, and the fixed variance of Gauss kernel function cannot remove all kinds of noise. The level set curve could not locate accurately. The subregions in the object are separated using the CV model. Furthermore, the results of segmentation become terrible with lower PSNR. Compared to the ground truth, the positional accuracy of the segmentation curve using the proposed method is higher than that of the TB model. The edge-preserving parameter preserves edges and smooths subregions, according to local information. The scores of different models with different PSNR are shown in Table 2. Fig. 10Comparison of the proposed method with Li’s models13 and the CV model8 on real images with noise. (a) The original image, (b) noisy image with PSNR=23.4, and (c) noisy image with PSNR=18.8. Row 1: noisy images and initial curves, row 2: segmentation results of the CV model, row 3: the segmentation results of Li’s model, row 4: segmentation results of the TB model, row 5: the segmentation results of the proposed model, and row 6: the ground truth.  Table 2The scores of different algorithms on noisy images (where Pre, Rec, and F-M denote precision, recall, and F-measure, respectively).
From Table 2, with decreasing image quality, the precise and the F-measure of these four segmentation models reduce. The variance of F-measure using the proposed method, Li’s model,15 the TB model,20 and the CV model8 are 0.015, 0.081, 0.047, and 0.043, respectively. The variance of F-measure using the proposed method is smaller than those of other three models. The mean of the F-measure using the proposed method, Li’s model, the TB model, and the CV model are 0.892, 0.745, 0.878, and 0.829, respectively. The mean of F-measure using the proposed method is higher than those of other three models. It shows that our proposed method is insensitive to noise. Although the proposed method is insensitive to noise, the computer time is longer than that of other three models. The CPU time comparison of segmentation on an image with noise is shown in Table 3. Table 3The comparison of CPU time (in seconds) with noisy images.
To test robustness against salt-and-pepper noise of the proposed method, segmented experiments on a degraded image are conducted and compared with Li’s model,15 the TB model,20 and the CV model.8 Partial results are shown in Fig. 11. The linear smoothing (Gauss smoothing) cannot effectively remove salt-and-pepper noise, so Li’s segmentation curve could not converge with the object contour, and the F-Measure is 0.849. The CV model could converge with the object contour, but oversegmentation exists, the F-measure is 0.909, and the recall is 0.853; nonlinear smoothing (TV or median filter) can effectively remove the salt-and-pepper noise, the precisions of the proposed model and the TB model are 0.994 and 0.986, respectively. In the TB model, the TV smoothing and the smoothing-component segmentation are individual steps. It could not adaptively adjust the relationship between the number of smoothing iteration and region-confidence level. The F-measure of the proposed method is 0.98, and 0.021 higher than that of TB model. Fig. 11Comparison of the proposed method with Li’s models13 and the CV model8 on real images with salt-and-pepper noise. (a) Initial curves, (b) the ground truth, (c) the proposed model, (d) the segmentation results of the CV model, (e) the segmentation results of the Li’s model, and (f) segmentation results of the TB model.  6.Concluding RemarksTo improve segmentation performance of the active contour model on real images, we propose an image segmentation model based on edge-preserving smoothing. Compared to Li’s model, the CV model, and TB model on real images, the experimental results have shown that this method is insensitive to noise and can deal with inhomogeneous subregions. However, the proposed edge-preserving smoothing just retains the edge information, but could not sharpen weak edges. Thus, the proposed method cannot precisely locate the object contour formed by a weak edge. Furthermore, the computational cost is high. In the future, we plan to design an efficient model to sharpen the weaken edge. AcknowledgmentsThis work was supported by the Sichuan Province Natural Science Foundation of China (Grant No. 2013SZ0157). The author Kun He and the author Dan Wang give the improved algorithm and the structure of the article. The algorithm implementation and the article writing are collaborative efforts. Partial experimental results in the article are given by Xiuqing Zheng. ReferencesY. K. Sen et al.,
“Image segmentation methods for intracranial aneurysm haemodynamic research,”
J. Biomech., 47
(5), 1014
–1019
(2014). http://dx.doi.org/10.1016/j.jbiomech.2013.12.035 JBMCB5 0021-9290 Google Scholar
R. C. Zhao and Y. D. Ma,
“A novel region segmentation algorithm with neural network for segmented image coding,”
Acta Electron. Sin., 42
(7), 1277
–1283
(2014). http://dx.doi.org/10.3969/j.issn.0372-2112.2014.07.006 TTHPAG 0372-2112 Google Scholar
M. Caon et al.,
“Computer-assisted segmentation of CT images by statistical region merging for the production of voxel models of anatomy for CT dosimetry,”
Australas. Phys. Eng. Sci. Med., 37
(2), 393
–403
(2014). http://dx.doi.org/10.1007/s13246-014-0273-x Google Scholar
X. Yang et al.,
“Improving level set method for fast auroral oval segmentation,”
IEEE Trans. Image Process., 23
(7), 2854
–2865
(2014). http://dx.doi.org/10.1109/TIP.2014.2321506 IIPRE4 1057-7149 Google Scholar
J. B. Shen, Y. F. Du and X. L. Li,
“Interactive segmentation using constrained Laplacian optimization,”
IEEE Trans. Circuits Syst. Video Technol., 24
(7), 1086
–1099
(2014). http://dx.doi.org/10.1109/TCSVT.2014.2302545 ITCTEM 1051-8215 Google Scholar
M. W. Khan,
“A survey: image segmentation techniques,”
Int. J. Future Comput. Commun., 3
(2), 89
–93
(2014). http://dx.doi.org/10.7763/IJFCC.2014.V3.274 Google Scholar
L. Wang et al.,
“Joint segmentation and recognition of categorized objects from noisy web image collection,”
IEEE Trans. Image Process., 23
(9), 4070
–4086
(2014). http://dx.doi.org/10.1109/TIP.2014.2339196 IIPRE4 1057-7149 Google Scholar
T. F. Chan and L. Vese,
“Active contours without edges,”
IEEE Trans. Image Process., 10
(2), 266
–277
(2001). http://dx.doi.org/10.1109/83.902291 IIPRE4 1057-7149 Google Scholar
D. Mumford and J. Shah,
“Optimal approximations of piecewise smooth functions and associated variational problems,”
Commun. Pure Appl. Math., 42
(5), 577
–685
(1989). http://dx.doi.org/10.1002/(ISSN)1097-0312 CPMAMV 0010-3640 Google Scholar
A. Tsai et al.,
“Curve evolution implementation of the mumford-shah functional for image segmentation, denoising, interpolation, and magnification,”
IEEE Trans. Image Process., 10
(8), 1169
–1186
(2001). http://dx.doi.org/10.1109/83.935033 Google Scholar
C. Li et al.,
“Implicit active contours driven by local binary fitting energy,”
in Proc. IEEE Conf. on Computer Vision and Pattern recognition,
1
–7
(2007). http://dx.doi.org/10.1109/CVPR.2007.383014 Google Scholar
Y. Peng et al.,
“Active contours driven by normalized local image fitting energy,”
J. Syst. Eng. Electron., 25
(2), 307
–313
(2014). http://dx.doi.org/10.1109/JSEE.2014.00035 Google Scholar
H. Y. Jiang and R. J. Feng,
“Image segmentation method research based on improved variational level set and region growth,”
Acta Electron. Sin., 40
(8), 1659
–1664
(2012). http://dx.doi.org/10.3969/j.issn.0372-2112.2012.08.026 TTHPAG 0372-2112 Google Scholar
D. Kong and G. Wang,
“Region-similarity based active contour model for SAR image segmentation,”
J. Comput.-Aided Des. Comput. Graphics, 22
(9), 1554
–1560
(2010). Google Scholar
C. Li et al.,
“Level set evolution without re-initialization: a new variational formulation,”
in the Proc. of the 2005 IEEE Computer Society Conf. on Computer Vision and Pattern Recognition,
430
–436
(2005). http://dx.doi.org/10.1109/CVPR.2005.213 Google Scholar
Q. Wen et al.,
“Decomposition and active contour method for medical noise image segmentation,”
J. Comput.-Aided Des. Comput. Graphics, 23
(11), 1882
–1889
(2011). Google Scholar
S. Y. Yeo et al.,
“Segmentation of biomedical images using active contour model with robust image feature and shape prior,”
Int. J. Numer. Methods Biomed. Eng., 30
(2), 232
–248
(2014). http://dx.doi.org/10.1002/cnm.2600 Google Scholar
T. F. Chan, S. Osher and J. H. Shen,
“The digital TV filter and nonlinear denoising,”
IEEE Trans. Image Process., 10
(2), 231
–241
(2001). http://dx.doi.org/10.1109/83.902288 IIPRE4 1057-7149 Google Scholar
L. Evans, Partial Differential Equations, American Mathematical Society, Providence
(1998). Google Scholar
K. He, X. Q. Zheng and Y. L. Zhang,
“Image segmentation on texture blurring,”
J. Sichuan Univ., 47
(4), 111
–117
(2015). http://dx.doi.org/10.15961/j.jsuese.2015.04.016 Google Scholar
BiographyKun He received his PhD in electrical and computer engineering from Sichuan University in 2006. Since 2006, he has been working as a professor research fellow in the School of Computer Science, Sichuan University. His research interests include pattern recognition, computer vision, and image processing. Dan Wang received the bachelor's degree in software engineering from Sichuan University in 2014. She is currently a graduate student of the software engineer, the Key National Defense Laboratory of Visual Synthesis Graphic and Image, Sichuan University. Her major work was pattern recognition, image processing, and medical image analysis. Xiuqing Zheng received her PhD in computer science and technology, Sichuan University. Currently, she served as the associate dean of Applied Technology College in Sichuan Normal University. Her research interests include intelligent information processing and image processing. She has undertaken and presided over many scientific and technological projects. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||