|
|
1.IntroductionWith the development of artificial intelligence and affective computing, facial expression recognition has shown prospects in human–computer interfaces, online education, entertainment, intelligent environments, and so on. In past years, much research has been done on the data collected in strictly controlled laboratory settings with frontal faces, perfect illumination, and posed expressions. As the application environment turns into a real world scenario, those methods using the monomial feature such as local binary patterns (LBP)1 or bag of visual words2 cannot achieve promising results. In addition, unlike the lab-controlled dataset, human heads in a real environment can be in any position of an image with all sorts of angles and poses. So, for most automatic facial expression recognition methods, the first step is to locate and extract the position of a face in the whole scene. The traditional way of this progress is always to combine the Viola–Jones face detector and the Haar-cascade eye detector.3 Recently, some methods, such as mixture of parts (MoPs)4 and supervised descent method,5 have robust face detection results in various head rotations. To explore facial expression recognition in the real world, we do experiments on three public datasets: acted facial expression in the wild (AFEW), static facial expression in the wild (SFEW), and facial expression recognition (FER). The AFEW database6 consists of short video clips extracted from popular Hollywood movies. Each clip contains a film actor who has been labeled into one of the seven basic facial expression categories, namely Anger, Disgust, Fear, Happiness, Neutral, Sadness, and Surprise. The AFEW set has 711 training videos, 371 validation videos, and 539 test videos. We only know the labels of the training and validation sets, specific numbers of which are shown in Table 1. The SFEW database7 is almost the same as that of the AFEW set, except that it consists of static frames of the movies. Both of the datasets are very challenging for traditional facial expression recognition methods due to the complicated scenes of films, which can be seen from the uncompromising baseline recognition rate of 36.08% and 35.96%. The SFEW set consists of 891,427, and 372 RGB color images for training, validation, and testing, respectively. Samples of expression data are shown in Fig. 1. The FER-2013 dataset8 is a facial expression dataset created using the Google image search application programming interface to search for images of faces that match a set of 184 emotion-related keywords such as “blissful” and “enraged.” It has 28,709 gray images for training and 7178 images for validation. On the FER dataset, the human accuracy was . Fig. 1Samples of facial expression data of SFEW. The expressions shown are from the first line left to second line right, anger, disgust, fear, happiness, neutral, sadness, and surprise. The image data are quite different in the illumination status and character postures.  Table 1The number of data for each expression in AFEW, SFEW, and FER dataset.
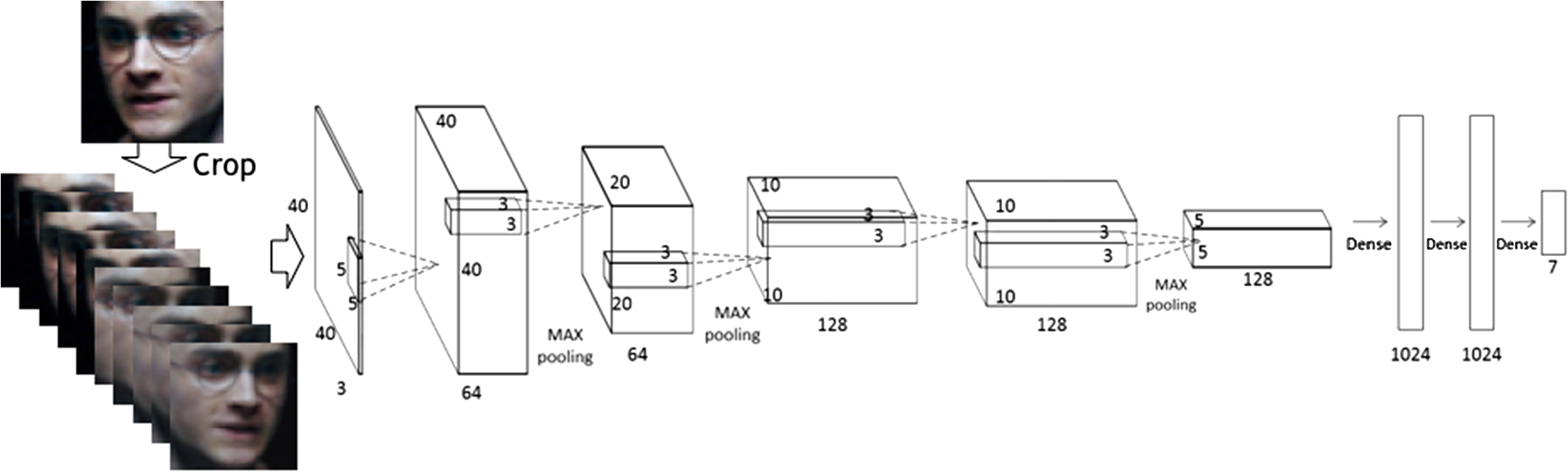
In our proposed method, openly available tools such as MoPS4 and Intraface5 are used for face detection and alignment. For facial expression, we employ the descriptors of LBP,1 local phase quantization (LPQ),9 histogram of oriented gradients (HOG),10 and dense scale-invariant feature transform (SIFT).2 We also design a deep convolutional neural network (CNN)11 for feature learning and compare the recognition results between gray data and color data. Then, we propose a fusion network for classification, which is a decision-level fusion method for improving the result. Our fusion network fuses different features and gains a promising recognition performance. We also compare the result of it with that of other state-of-the art fusion methods. The rest of this paper is organized as follows: In Sec. 2, we review the related works. The facial image extraction progress is shown in Sec. 3. Section 4 details the deep features and handcrafted features we explored. Section 5 gives the definitions of the proposed feature fusion network. Section 6 gives the experiments we have done, in which the feature components and the recognition results on three datasets are available. Then, the final conclusion is given in Sec. 7. 2.Related WorksThere are many researches focusing on recognizing facial expression. Ekman and Friesen12 defined facial action coding system action units for manual facial expression analysis. Zhao and Pietikainen1 proposed a volume local texture feature LBP-TOP and achieved remarkable facial expression recognition results in a laboratory. Kahou et al.13 used convolutional neural network and deep belief network and got the top performance in the EmotiW 2013 Challenge. Liu et al.14 used Grassmannian Manifold to get facial expression features, then they combined Riemannian Manifold and deep convolutional neural network in Ref. 15. Yao et al.16 combined the CNN model with facial action unit aware features and got the state-of-the-art result for facial expression recognition in videos. Kim et al.17 explored several CNN architectures and data preprocessing methods. Yu and Zhang18 used a data disturb method to enhance data. Liu et al.19 proposed a boosted deep belief network for facial expression recognition and got promising results on some laboratory recorded datasets. Ng et al.20 explored transfer learning for deep models including VGG and AlexNet.21 Since no feature descriptor can handle the problem of facial expression recognition in the wild alone, the fusion method can be used to combine multimodal features. Sikka et al.22 explored the fusion way of general multiple kernel learning (GMKL) and multi-label multiple kernel learning. Chen et al.23 used the SimpleMKL method to combine visual and acoustic features. Kim et al.17 proposed a committee machine method to combine 108 CNN models in. Kahou et al.24 proposed a voting matrix and used random search to tune the fusion weight parameters. They used the multilayer perceptron in Ref. 25 to combine neural networks at the feature level. Gönen and Alpaydın26 reviewed quite a few kinds of multiple kernel methods for the common pattern recognition problem. Bucak et al.27 reviewed the state-of-the-art for multiple kernel learning (MKL), with the focus on the applications of object recognition. 3.Face ExtractionWe follow the face extraction and tracking method of Sikka et al.2 and Dhall et al.28 For the continuous facial expression recognition, the mixture of tree structured part model (MoPS)4 face detector is used to detect the position of a face in the first frame of a video. Then, the IntraFace toolkit used the supervised descent method5 to track 49 facial landmarks of the rest of the frames in a parameterized appearance model. All frames of the AFEW dataset are aligned to a base face through affine transformation and cut to . For the static facial expression recognition, the MoPS and OpenCV29 detectors are used for SFEW and FER, respectively. Facial landmarks generated by MoPS are used to align faces for handcrafted features extraction. For deep CNN features that are robust to the poses of faces, only coarse face alignment is performed, by keeping the center of facial landmark points or bounding boxes at the middle of images. All face images are resized to for deep feature learning. For handcrafted features, the image size is set to . As illumination and brightness changes appeared frequently in the SFEW dataset, we evaluate the min–max normalization as image preprocessing method. 4.Multimodal Texture Features4.1.Feature LearningThe deep CNN11 is a popular type of model in the community of computer vision. We deploy two kinds of CNN architectures, the AlexNet and regions CNN (RCNN). The AlexNet21 is a nine-layers deep model designed for object recognition of ImageNet dataset,30 using rectified linear unit as activation function. The AlexNet model has five convolutional layers and three fully connection layers. It introduces data enlarge strategy, local normalization, and dropout method to avoid over-fitting. The RCNN31 is a type of deep learning architecture that combines object detection with object recognition. This model can detect the object in a scene and then use the CNN feature for classification. These two models are all pretrained on the ImageNet dataset. Based on the AlexNet, we design a deep CNN architecture for facial expression recognition. The whole architecture of our model is shown in Fig. 2. First, the facial images are cropped from four corners and the center and flipped to 10 patches of . Then, the first convolutional layer filters the input patch with 64 kernels of size . The second convolutional layer takes as input the response-normalized and max-pooled output of the first convolutional layer and filters it with 64 kernels of size . The third, fourth, and fifth convolutional layers are connected to one another without any intervening pooling or normalization layers. The third convolutional layer has 128 kernels of size connected to the (normalized, pooled) outputs of the second convolutional layer. The fourth and fifth convolutional layers both have 128 kernels of size . The fully connected (FC) layers have 1024 neurons each. The rectified linear unit activations are applied to the output of every convolutional or fully connected layer. For validation of the training progress, the softmax regression is used as the output layer. For feature extraction, we use the last FC layer as the output. In our experiments, we visualize the activation values of the first convolutional layers of the AlexNet and our proposed CNN, which are shown in Fig. 3. We can see that some feature maps of the AlexNet are not activated in the task of expression recognition. This is reasonable since the AlexNet is trained on the ImageNet dataset, which makes its feature contain more information than human facial expression. 4.2.Handcrafted FeaturesFor images of SFEW dataset, we extract LBP, dense SIFT, and deep CNN features. For video clips of AFEW dataset, we extract volume features such as LBP-TOP, LPQ-TOP and pooling the dense SIFT, HOG and DCNN features through the image sequences of a video. In addition, we also design two temporal–spatial features: SIFT-TOP and SIFT-LBP. The pipeline of extracting these handcrafted features is as follows: on the face images extracted from a video, alignment through facial landmark points and spatial pyramid matching (SPM) are performed, and then features are encoded after extraction. The pipeline is shown in Fig. 4. Fig. 4Pipeline of handcrafted features extraction. The dashed box means that the temporal–spatial representation is only used for AFEW dataset.  4.2.1.Image descriptorsThe LBP descriptor is an efficient representation of facial image texture, and has been successfully applied to facial expression recognition.1 It can be represented as follows: In Eq. (1), means the Boolean comparison between a pixel and its neighboring pixels which has a total number of . The binary labels form a local binary pattern over the whole pixels of an image. The LPQ9 descriptor is calculated based on computing short-term Fourier transform on local image window. The descriptor utilizes phase information computed locally in a window for every image position. The phases of the four low-frequency coefficients are decorrelated and uniformly quantized in an eight-dimensional space. The HOG10 is implemented by dividing the image window into small spatial regions, each region accumulating a local one-dimensional histogram of gradient directions or edge orientations over the pixels of the region. The combined histogram entries form the representation. The dense SIFT feature32 is to perform SIFT descriptor on a dense gird of locations at a fixed scale and orientation. The SIFT descriptor associates to the gird a signature that identifies its appearance compactly and robustly. The dense SIFT feature characterizing appearance information is often used for categorization task. 4.2.2.Feature encoding and pyramid matchingFor LBP and LPQ descriptor, histograms of all binary codewords are formed to encode the final image features. Take note that only the statistics of 59 uniform local binary patterns1 are considered. For dense SIFT descriptor, the bag of words model has shown remarkable performance on facial expression recognition.22 First, we extract multiscale dense SIFT descriptors32 from 100 randomly picked image samples. Then, 800 clustering centers are constructed using approximate -means clustering algorithm. The number 800 is chosen throughout the experiments. Then, the whole data sets’ dense SIFT descriptors are encoded using the locality-constrained linear coding (LLC),33 which can guarantee the sparsity and locality of the coded words. In our experiments, we tried spatial pyramid matching34 for the handcrafted descriptors. Experimental results show that spatial pyramid matching can add recognition accuracy by providing more spatial information to the final features. The number of layers of LBP, LPQ, and dense SIFT are 4, 4, and 5, respectively. 4.3.Temporal–Spatial RepresentationFor continuous facial expression recognition, the image feature has to be extended to temporal–spatial area. After getting the image features of all image frames of a video clip, max pooling is usually used to aggregate all frame features into one video feature. Though this is still decent performance, it actually loses much detailed temporal information of a video. Based on deep analysis on our experiments, we add temporal information through extracting LBP descriptors on the and planes (in which stands for the time domain) of a video, and combine it with the dense-SIFT feature of plane (i.e., the image space) (SIFT-LBP), shown as Fig. 5. LBP descriptors of and frames are encoded to histogram and histogram, after spatial pyramid matching. Bag of multiscale dense SIFT feature is extracted from every frame following the pipeline described in Sec. 4.2.2. We also explore how to directly extract dense SIFT feature on the three orthogonal planes of , , and (SIFT-TOP). Our experiment shows that the new temporal–spatial descriptor, namely SIFT-LBP, has better performance. We also explore how to use a deep learnt feature for temporal–spatial representation, which is accomplished by taking the maximum pooling value of the CNN feature vectors over all frames. Unfortunately, the recognition result is uncompromising on the AFEW dataset. 5.Fusion Classification5.1.Classifiers5.1.1.Support vector machineThe features we extract are all linearly separable under ideal conditions. So, we use linear support vector machine (SVM) as basic classifiers. Given a training set of data points (), , , , the support vector classifier solves the following unconstrained optimization problem:35 where is the penalty parameter and is the loss function. For testing data , SVM predicts it as positive if , and negative otherwise. Here, we use the SVM decision value as the input for the next fusion process. As SVM is a binary classifier, we follow one-versus-rest strategy, which classifies the data points between one category and the rest one at a time.5.1.2.Partial least squares regressionPartial least squares (PLS) regression is a statistical method that bears some relation to principal components regression; instead of finding hyperplanes of minimum variance between the response and independent variables, it finds a linear regression model by projecting the predicted variables and the observable variables to a new space. According to Ref. 14 given a feature set with label , the PLS classifier decomposes these variables into: where and contain the extracted score vectors, and are orthogonal loading matrices, and and are residuals. PLS tries to find the optimal weights and to get the maximum covariance such thatThen, we can get the regression coefficients as The PLS decision value can be estimated by . Like in Sec. 5.1, we follow one- versus-rest strategy for the multiclass classification. 5.2.Fusion NetworkAs different features have different discriminative abilities on specific emotions,36 we propose a fusion network as shown in Fig. 6 to combine the results of each classifier. Given features and classes, the SVM or PLS classifiers generate decision values, which can be denoted as , , . Then, they are used as the input for the fusion network. For input , we use a hypothesis function to estimate , which represents the probability of the class label taking on each of the different possible values. Here, means weights. Thus, the final output is an dimensional vector, which represents probabilities. The final prediction is using a max-win strategy to choose the most likely label.We use a loss function for optimization. The gradient descent method is applied to get the optimized values of by updating to at every iteration where is the number of training examples, is the L2-norm parameter, is the indicator function, which means , and .In experiments, we try to fuse the decision values of SVM and PLS classifiers. We find that this kind of fusion network performs better than the SVM-only fusion network. 6.Experiments6.1.Deep Feature Learning of Color and Gray ImagesFor deep feature learning, we employ the Caffe37 implementation, which is commonly used in several recent works. To pretrain the CNN model according to our proposed architecture, we use expression images from the FER dataset. The base learning rate is set to 0.005, which will be divided by 10 after every 10,000 iterations. In each iteration, 256 samples are used for stochastic gradient optimization. After 200 epoch’s training, our proposed CNN gets 67.82% on the FER validation set. Then, we fine-tune the model on the SFEW set. The base learning rate is changed to 0.001. After 300 epoch’s fine-tuning, the validation accuracy is converged. The experiment results are shown in Table 2. We can see that the RGB color CNN model with min–max normalization can achieve slightly better recognition result. Table 2Comparison results of proposed CNN model, on color and gray image data.
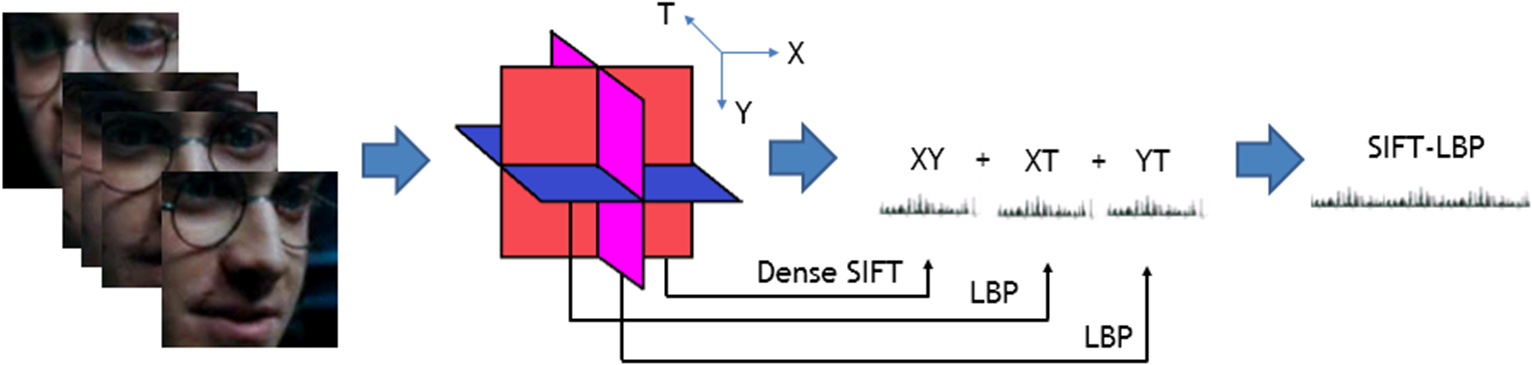
6.2.Results of Monomial FeatureWe extract the features listed in Sec. 4 and apply the SVM and PLS classifiers. Results are shown in Tables 3 and 4. On the SFEW dataset, through comparison experiments, we extract the last pooling layer’s activation value as the feature of AlexNet and RCNN. For our proposed CNN, the last fully connected layer’s output is extracted. We can see that using the SVM and PLS classifier can further improve the recognition result of the CNN model. On the AFEW dataset, as each frame produces a CNN, a dense SIFT and a HOG feature vector, information from all frames of a video are combined using pooling strategy, which is accomplished by taking the maximum or mean value of all feature vectors over all frames. By experiment, max pooling has better results for dense SIFT and HOG. The SVM classifiers all use linear kernels. Classification models are trained on training set and parameters are tuned on validation set through a fivefold cross validation in the range from to . Results show that our proposed CNN feature and SIFT-LBP feature performs well on the SFEW and AFEW dataset, respectively. Table 3Recognition accuracies on SFEW, C is the cost parameter of SVM, n is the PLS dimension. P represents the activation value of last pooling layer while FC means the activation value of last FC layer.
Table 4Recognition accuracies on AFEW.
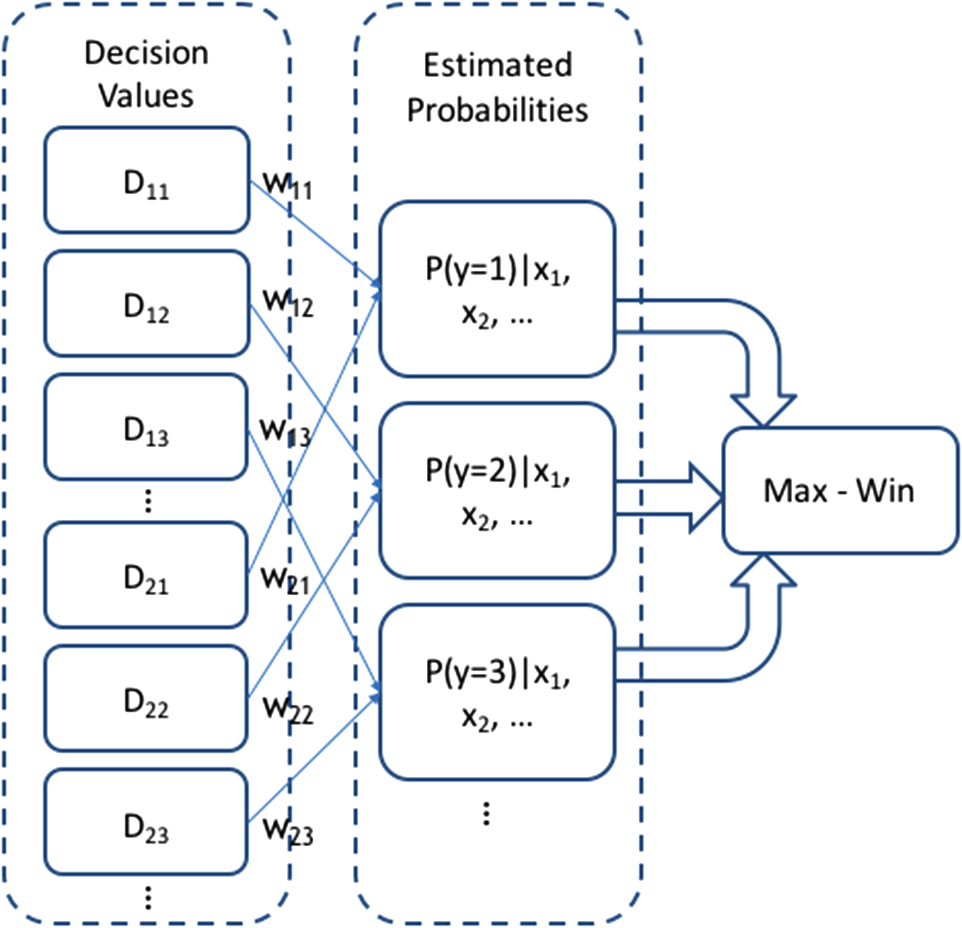
For AFEW and SFEW datasets, we use four-Layer SPM for LBP and LPQ features. Each image is partitioned into segments at multiple scales , and 8. For example, the dimension of SPM-LBPTOP is 15,045. Too much SPM layers mean lager dimension and it would be harder to be optimized for classification. While as dense SIFT uses LLC coding, five-layer SPM can achieve the best performance. 6.3.Fusion Results of Multimodal FeaturesThen, our proposed fusion network is performed to combine the classification results of these features. We train the fusion network on the validation set. The L2-norm parameter is chosen through a cross validation on the validation set. Fusion results are shown in Tables 5 and 6. Results show that our proposed method is better both on the validation set and testing set. We compare the fusion network with GMKL,38 SimpleMKL,39 and three other researcher’s work17,18,20 on the SFEW set. We can see that our fusion network outperforms other methods on the validation set. As the test labels of the AFEW and SFEW datasets are not publicly opened, we do not get final test results for all our methods. Despite that we can see that our proposed fusion network performs well and robust through cross validation. Note that some features perform better when classified by PLS, so the fusion network combining PLS and SVM together can achieve better results than using only SVM. Table 5Fusion results on SFEW dataset. The SVM fusion network means the fusion of SVM results only. In the fusion network, AlexNet and RCNN features are classified by PLS.
Table 6Fusion results on AFEW dataset. In the fusion network, the LPQ-TOP is classified by PLS.
7.Conclusions and Future WorkIn this paper, we design some texture features for automatic human facial expression recognition in the real world. For each feature, we train individual SVM and PLS classifiers that have different discriminative ability for facial expressions classification. We propose a fusion network to utilize these feature characteristics. The method is evaluated on the AFEW and SFEW datasets and gains very promising achievement. In the future, we will try to deduce more kinds of temporal–spatial representation methods to further improve the continuous facial expression recognition result and investigate the use of component analysis methods to decrease the feature dimensions. AcknowledgmentsThis work was supported by the National Natural Science Foundation of China (Grant Nos. 61501035 and KJZXCJ2016042), the Fundamental Research Funds for the Central Universities of China (2014KJJCA15), and the National Education Science Twelfth Five-Year Plan Key Issues of the Ministry of Education (DCA140229). ReferencesG. Zhao and M. Pietikainen,
“Dynamic texture recognition using local binary patterns with an application to facial expressions,”
IEEE Trans. Pattern Anal. Mach. Intell., 29
(6), 915
–928
(2007). http://dx.doi.org/10.1109/TPAMI.2007.1110 ITPIDJ 0162-8828 Google Scholar
K. Sikka et al.,
“Exploring bag of words architectures in the facial expression domain,”
in Computer Vision–ECCV 2012. Workshops and Demonstrations,
250
–259
(2012). Google Scholar
M. F. Valstar et al.,
“The first facial expression recognition and analysis challenge,”
in IEEE Int. Conf. on Automatic Face & Gesture Recognition and Workshops (FG 2011),
921
–926
(2011). http://dx.doi.org/10.1109/FG.2011.5771374 Google Scholar
X. Zhu and D. Ramanan,
“Face detection, pose estimation, and landmark localization in the wild,”
in 2012 IEEE Conf. on Computer Vision and Pattern Recognition (CVPR),
2879
–2886
(2012). http://dx.doi.org/10.1109/CVPR.2012.6248014 Google Scholar
X. Xiong and F. De la Torre,
“Supervised descent method and its applications to face alignment,”
in IEEE Conf. on Computer Vision and Pattern Recognition (CVPR),
532
–539
(2013). http://dx.doi.org/10.1109/CVPR.2013.75 Google Scholar
A. Dhall et al.,
“Collecting large, richly annotated facial-expression databases from movies,”
IEEE Multimedia, 19
(3), 34
–41
(2012). http://dx.doi.org/10.1109/MMUL.2012.26 IEMUE4 Google Scholar
A. Dhall et al.,
“Static facial expression analysis in tough conditions: data, evaluation protocol and benchmark,”
in IEEE Int. Conf. on Computer Vision Workshops (ICCV Workshops),
2106
–2112
(2011). http://dx.doi.org/10.1109/ICCVW.2011.6130508 Google Scholar
I. J. Goodfellow et al.,
“Challenges in representation learning: a report on three machine learning contests,”
Neural Information Processing, 117
–124 Springer, Berlin Heidelberg
(2013). Google Scholar
J. Päivärinta, E. Rahtu, J. Heikkilä,
“Volume local phase quantization for blur-insensitive dynamic texture classification,”
Image Analysis, 360
–369 Springer, Berlin Heidelberg
(2011). Google Scholar
N. Dalal and B. Triggs,
“Histograms of oriented gradients for human detection,”
in IEEE Computer Society Conf. on Computer Vision and Pattern Recognition (CVPR 2005),
886
–893
(2005). http://dx.doi.org/10.1109/CVPR.2005.177 Google Scholar
Y. LeCun, Y. Bengio and G. Hinton,
“Deep learning,”
Nature, 521
(7553), 436
–444
(2015). http://dx.doi.org/10.1038/nature14539 Google Scholar
P. Ekman and E. L. FriesenRosenberg, What the face reveals: Basic and applied studies of spontaneous expression using the Facial Action Coding System (FACS), Oxford University Press(1997). Google Scholar
S. E. Kahou et al.,
“Combining modality specific deep neural networks for emotion recognition in video,”
in Proc. of the 15th ACM on Int. Conf. on Multimodal Interaction,
543
–550
(2013). Google Scholar
M. Liu et al.,
“Partial least squares regression on Grassmannian manifold for emotion recognition,”
in Proc. of the 15th ACM on Int. Conf. on Multimodal Interaction,
525
–530
(2013). Google Scholar
M. Liu et al.,
“Combining multiple kernel methods on Riemannian manifold for emotion recognition in the wild,”
in Proc. of the 16th Int. Conf. on Multimodal Interaction,
494
–501
(2014). Google Scholar
A. Yao et al.,
“Capturing au-aware facial features and their latent relations for emotion recognition in the wild,”
in Proc. of the 2015 ACM on Int. Conf. on Multimodal Interaction,
451
–458
(2015). Google Scholar
B. K. Kim et al.,
“Hierarchical committee of deep convolutional neural networks for robust facial expression recognition,”
J. Multimodal User Interfaces, 10
(2), 173
–189
(2016). http://dx.doi.org/10.1007/s12193-015-0209-0 Google Scholar
Z. Yu and C. Zhang,
“Image based static facial expression recognition with multiple deep network learning,”
in Proc. of the 2015 ACM on Int. Conf. on Multimodal Interaction,
435
–442
(2015). Google Scholar
P. Liu et al.,
“Facial expression recognition via a boosted deep belief network,”
in IEEE Conf. on Computer Vision and Pattern Recognition (CVPR 2014),
1805
–1812
(2014). http://dx.doi.org/10.1109/CVPR.2014.233 Google Scholar
H. W. Ng et al.,
“Deep learning for emotion recognition on small datasets using transfer learning,”
in Proc. of the 2015 ACM on Int. Conf. on Multimodal Interaction,
443
–449
(2015). Google Scholar
A. Krizhevsky, I. Sutskever and G. E. Hinton,
“Imagenet classification with deep convolutional neural networks,”
Advances in Neural Information Processing Systems, 1097
–1105 2012). Google Scholar
K. Sikka et al.,
“Multiple kernel learning for emotion recognition in the wild,”
in Proc. of the 15th ACM on Int. Conf. on Multimodal Interaction,
517
–524
(2013). Google Scholar
J. Chen et al.,
“Emotion recognition in the wild with feature fusion and multiple kernel learning,”
in Proc. of the 16th Int. Conf. on Multimodal Interaction,
508
–513
(2014). Google Scholar
S. E. Kahou et al.,
“Combining modality specific deep neural networks for emotion recognition in video,”
in Proc. of the 15th ACM on International conference on multimodal interaction,
543
–550
(2013). Google Scholar
S. E. Kahou et al.,
“Recurrent neural networks for emotion recognition in video,”
in Proc. of the 2015 ACM on Int. Conf. on Multimodal Interaction,
467
–474
(2015). http://dx.doi.org/10.1145/2818346.2830596 Google Scholar
M. Gönen and E. Alpaydın,
“Multiple kernel learning algorithms,”
J. Mach. Learn. Res., 12 2211
–2268
(2011). Google Scholar
S. S. Bucak, R. Jin and A. K. Jain,
“Multiple kernel learning for visual object recognition: a review,”
IEEE Trans. Pattern Anal. Mach. Intell., 36
(7), 1354
–1369
(2014). http://dx.doi.org/10.1109/TPAMI.2013.212 ITPIDJ 0162-8828 Google Scholar
A. Dhall et al.,
“Video and image based emotion recognition challenges in the wild: Emotiw 2015,”
in Proc. of the 2015 ACM on Int. Conf. on Multimodal Interaction,
423
–426
(2015). Google Scholar
G. Bradski,
“The open CV library,”
Doctor Dobbs J., 25
(11), 120
–126
(2000). Google Scholar
O. Russakovsky et al.,
“Imagenet large scale visual recognition challenge,”
Int. J. Comput. Vision, 115
(3), 211
–252
(2014). IJCVEQ 0920-5691 Google Scholar
R. Girshick et al.,
“Rich feature hierarchies for accurate object detection and semantic segmentation,”
in IEEE Conf. on Computer Vision and Pattern Recognition (CVPR 2014),
580
–587
(2014). Google Scholar
A. Vedaldi and B. Fulkerson,
“VLFeat: an open and portable library of computer vision algorithms,”
in Proc. of the Int. Conf. Multimedia,
1469
–1472
(2010). Google Scholar
J. Wang et al.,
“Locality-constrained linear coding for image classification,”
in IEEE Conf. on Computer Vision and Pattern Recognition (CVPR 2010),
3360
–3367
(2010). http://dx.doi.org/10.1109/CVPR.2010.5540018 Google Scholar
S. Lazebnik, C. Schmid and J. Ponce,
“Beyond bags of features: spatial pyramid matching for recognizing natural scene categories,”
in 2006 IEEE Computer Society Conf. on Computer Vision and Pattern Recognition (CVPR'06),
2169
–2178
(2006). http://dx.doi.org/10.1109/CVPR.2006.68 Google Scholar
R. E. Fan et al.,
“LIBLINEAR: a library for large linear classification,”
J. Mach. Learn. Res., 9 1871
–1874
(2008). http://dx.doi.org/10.1145/1390681.1442794 Google Scholar
B. Sun et al.,
“Combining multimodal features with hierarchical classifier fusion for emotion recognition in the wild,”
in Proc. of the 16th Int. Conf. on Multimodal Interaction,
481
–486
(2014). Google Scholar
Y. Jia et al.,
“Caffe: convolutional architecture for fast feature embedding,”
in Proc. of the ACM Int. Conf. on Multimedia,
675
–678
(2014). Google Scholar
M. Varma and B. R. Babu,
“More generality in efficient multiple kernel learning,”
in Proc. of the 26th Annual Int. Conf. on Machine Learning,
1065
–1072
(2009). Google Scholar
A. Rakotomamonjy et al.,
“SimpleMKL,”
J. Mach. Learn. Res., 9 2491
–2521
(2008). Google Scholar
BiographyBo Sun received his BSc degree in computer science from Beihang University, China, and his MSc and PhD degrees from Beijing Normal University, China. He is currently a professor in the Department of Computer Science and Technology, Beijing Normal University. His research interests include pattern recognition, natural language processing, and information systems. He is a member of ACM and a senior member of China Society of Image and Graphics. Liandong Li received his BSc degree in computer science and technology from Beijing Normal University, 2011. He is currently working toward the PhD in computer application technology at Beijing Normal University. His research interests include machine learning, computer vision, and emotion analysis. Guoyan Zhou received her BSc degree in computer science and technology from Beijing Normal University, 2013. Currently, she is working toward the MSc degree in computer application technology at Beijing Normal University. Her research interests include machine learning and computer vision. Jun He received her BSc degree in optical engineering and her PhD in physical electronics from Beijing Institute of Technology, Beijing, China, in 1998 and 2003, respectively. Since 2003, she has been with the College of Information Science and Technology, Beijing Normal University, Beijing, China. She was elected as a lecturer and an associate professor in 2003 and 2010, respectively. Her research interests include image processing application, and pattern recognition. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||