|
|
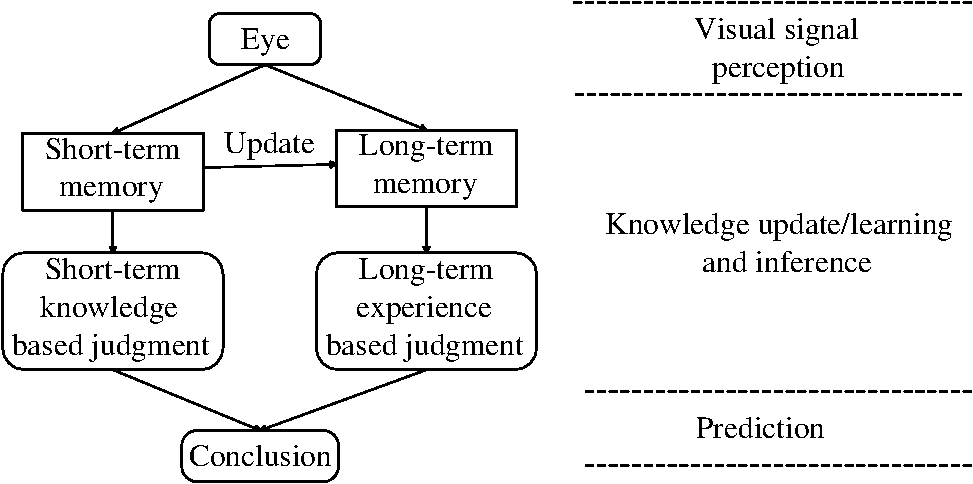
1.IntroductionScene annotation, as a primary goal of computer vision and robotic techniques involving many subtasks, such as depth estimation, saliency detection, and object annotation, has been intensely studied during the past few decades.1 Within this research field, Markov random field (MRF) is considered as a natural model for exploiting spatial priors.2,3 Recently, conditional random field4–6 has been widely utilized and has brought significant improvement in MRF. Another state-of-the-art method, max-margin Markov networks, effectively incorporates large margin mechanisms into MRF.7–9 Although scene analysis has been studied extensively during the past decade, improvement to it remains a critical challenge,10 largely because existing models do not have sufficient variability to describe the variable world, which restricts the application, field, and performance of existing methods. To solve this problem, based on traditional object classification method, we present a novel framework for scene annotation by incorporating three-dimensional (3-D) scene structure estimation, scene context, and cognitive theory. Studies on scene structure estimation aim to recover spatial information of a scene and estimate the position of objects. Context in an image encapsulates rich information on how natural scenes and objects relate to one another. Using contextual information has become popular in object recognition, as it enforces coherent scene interpretation and eliminates false positives to improve the accuracy of image classification.11–14 Most approaches can be classified into two general categories: (i) context inference based on statistical summary of the scene (scene-based context models) and (ii) context representation in terms of relationships among objects in the image (object-based context). Cognition is the brain faculty for processing information and applying knowledge in humans.15 Existing research shows that using biometric theory assists immensely in classification tasks.16 In our work, we study how humans attempt to comprehend a scene from the perspective of cognitive psychology and propose a flexible cognition-based hybrid motivation (CHM) framework, encompassing reasonable experience and assumption-based inference (EAI), and best-effort object labeling (BEL). EAI describes the common object appearing in an indoor scene, such as table, bed, and so on. In BEL, other objects are modeled and categorized in an abstract and hierarchical way, according to their context. A bag-of-visual words (BoVW)-based multilayer abstract semantics labeling (MASL) method is proposed to achieve this goal. Our approach is highly modularized, with no restrictions on its operation other than requiring the ability to train on data, making our method easy to extend and applicable to many other tasks with similar outputs. The paper is organized as follows. Relative research is concisely introduced in Sec. 2. Our CHM framework and MASL classification method are proposed in Sec. 3. Experimental results and analysis are provided in Sec. 4. Finally, we summarized our current and future work in Sec. 5. 2.Related ResearchIn general, object annotation is a process of learning to answer the “what” question from given images, and includes geometry recovery and object categorization. We will introduce them separately. 2.1.Room Geometry RecoveryA major challenge for indoor scene annotation is that most indoor scenes are cluttered by furniture and decorations, the appearances of which vary drastically across scenes. It is hard to model this characteristic consistently. The Manhattan world assumption states that there exist three dominant vanishing points that are orthogonal;17 this assumption has significantly reduced the difficulty of recovering space layout, and has benefited research in overcoming the challenge of indoor scene annotation immensely. The commonly used method is to recover the geometry of indoor scenes and to estimate the position of each object. The input samples include both single still image and video sequences.18–24 With the development of computer vision techniques, RGB-D images captured by devices such as Kinect can greatly reduce the difficulty and cost of generating 3-D scenes. Understandably, research studies are showing increasing interest in scanning and building 3-D scenes25–27 with RGB-D cameras. We will utilize the object detection method described by Hedau et al.28 to achieve the goal of object detection of an indoor scene. After this, the positions of most objects are established and will be utilized as input to the annotation method. 2.2.Object ClassificationObject classification has been an intensively studied field in computer vision for the past decades. Many outstanding studies and corresponding improvements have been carried out to solve this problem, such as k-nearest neighbors (KNN), decision tree, Bayes model, support vector machine, linear discriminant analysis, graph-based methods, and multiple-instance-based learning methods.29–32 Among these methods, BoVW33 is one of the most widely used methods due to its simplicity and effectiveness. In the learning model of BoVW, visual words are first obtained by k-means clustering local features. Then the image is represented by bag-of-features to train the classifier. However, it has four major drawbacks: (i) the quality of visual vocabulary is sensitive to data set size;34 (ii) spatial relationships of image patches are ignored during the construction of visual vocabulary;35 (iii) hard-assignment k-means clustering affects the generation of semantically optimized visual words;36 and (iv) performance of annotation is affected by semantic gap.37 In the previous work, there are four types of strategies for improving BoVW: segmentation, coding, ambiguity, and semantic compression. Segmentation-based methods utilize ROI to remove background that is irrelevant to visual word generation.38 Improvements to coding strategy39 and the introduction of ambiguity increase the descriptive ability of visual words.40 Local information is introduced to effectively generate complementary features.41 Semantic compression is proposed to improve efficiency and performance.42,43 Here, we target the semantic gap between visual features and semantic concepts to improve the performance of BoVW by dividing semantic concepts into several hierarchies to narrow semantic gaps. To train each concept classifier, visual vocabularies are extracted from samples of each inherited object class to train the abstract classes from bottom to top, and the model runs from top to bottom for classification. We will show this process in detail in Sec. 3. 3.CHM Scene Annotation FrameworkOne fascinating human characteristic is the ability to categorize objects with only a few labeled training instances and to infer the categories of an indoor scene despite its inner decoration. Humans are born with the ability to perform adaptive object categorization. Is it possible for a computer to achieve this goal with the support of machine learning techniques? To solve this problem, we will describe our framework in the following subsections. The framework can be roughly divided into two stages: first, the spatial layout of a scene is estimated and objects in the scene are detected; then the objects will be annotated by BoVW and the proposed MASL classification methods, respectively, according to the inference processes of humans. 3.1.Experience and Assumption-Based InferenceThe commonly accepted inference process of humans is shown in Fig. 1, according to the descriptions of cognitive theory.44 Long-term memory (LTM) operates like a huge knowledge warehouse serializing all kinds of information, whereas short-term memory (STM) contains a much smaller volatile storage space, and is the first point of handling of short-term knowledge learned from environmental stimulation. After knowledge in STM is serialized into LTM, key information is extracted to form or update experience for future use. If we encounter a novel object and cannot come to a conclusion about it from STM, LTM will be referred to if we do not immediately dismiss it. For example, when we see a cat for the first time, we will remember its key patterns and save them into both STM and LTM. Knowledge of the cat in STM may be overwritten by other knowledge since the space is limited. However, when we see a different cat, we will refer to LTM and recall its category. This is a very important ability in cognition. Generalization is an inherited ability for humans, consisting not only of the ability to extract patterns and learn from a limited number of samples, but also the ability to store common key information to ensure similar objects can be recognized in the future. It is a highly advanced skill compared with the ability of a computer; however, as we understand it, the inference process of a modern computer vision algorithm is a similar process as shown in Fig. 2. As demonstrated by the results of image categorization contests such as Pascal VOC challenge and the ImageNet large scale visual recognition challenge, the performance of object recognition algorithms has greatly improved in the last two decades of development. In some circumstances, the performance is good enough for practical purposes. However, compared with the natural human inference process, most methods in computer vision are STM-like, i.e., the LTM process is ignored, meaning object categorization methods are nonadaptive and inflexible. This is the main reason that humans, despite having one brain, can effectively recall and recognize many types of objects,44 while computers require training and adjusting many times over with different testing samples. In this paper, we propose a CHM object categorization framework for adaptive scene classification. Inspired by Porway et al.,45 we divide the problem of scene annotation into two steps for simplification: EAI and BEL. EAI simulates the experience-based inference ability of humans with manually set rules. For example, given the concept of “indoor scene,” despite the variation in detail of each indoor image, there are common objects that appear in our mind, such as wall, windows, tables, chairs, and so on, as shown in Fig. 3. First, we detect and categorize objects using EAI. The remaining objects are then detected and categorized by BEL with reasonable context to achieve higher-level adaptation. In EAI, objects are detected by Hedau et al.,28 then classified with BoVW. In BEL, the proposed MASL is adopted for classification and the model is ready to be extended for different situations. The introduction of EAI makes our approach a two-step flexible inference process, differing from other methods of indoor scene analysis.47–50 Fig. 3A common structure of indoor scenes provided by Quattoni and Torralba.46 We can see that although the decoration of each room is quite different, they share a similar structure and some common objects, e.g., wall, table, chair, window, etc.  3.2.BEL Object LabelingTo deal with objects exceeding the empirical field of EAI, inspired by Luo et al.,51 we propose a BoVW-based object classification method for BEL, known as MASL, by introducing semantic hierarchies with different levels of abstraction. It is modularly designed according to the organization of human memory,44 making it convenient to add knowledge from different object categories without affecting existing knowledge. The motivation for proposing the MASL categorization method is that the real world is powered by hierarchical structures, and relevant research has been proven effective.52 The difference between the previous method and MASL is the structure of abstraction. In MASL, the abstract layers are expandable instead of being a fixed frame. Furthermore, the abstraction techniques are introduced to generate layers with different abstract levels to describe the semantic concepts more clearly. Semantic hierarchies are helpful for image classification as they supply a hierarchical framework for image classification and provide extra information in both learning and representation.52 Three types of semantic hierarchy for image annotation have been recently explored: (1) language-based hierarchies based on textual information,53 (2) visual hierarchies based on low-level image features,54 and (3) semantic hierarchies based on both textual and visual features.55 Here, we extend BoVW by introducing middle and upper hierarchies of abstract semantics, which are constructed by semantics assigned visual words extracted from concrete categories (CCs). The hierarchical structure of BoVW and MASL is shown in Fig. 4. According to the principle, levels of abstraction increase from bottom to top. Consequently, descriptive ability increases while the difference between each CC is dimmed and common attributes are preserved. From the figure, we can see that MASL is a superset of BoVW. If the abstract hierarchies are omitted, MASL degrades into BoVW. Fig. 4Structure of bag-of-visual words (BoVW) and multilayer abstract semantics labeling (MASL) models. (a) The flat structure of BoVW. (b) Hierarchical structure of MASL. 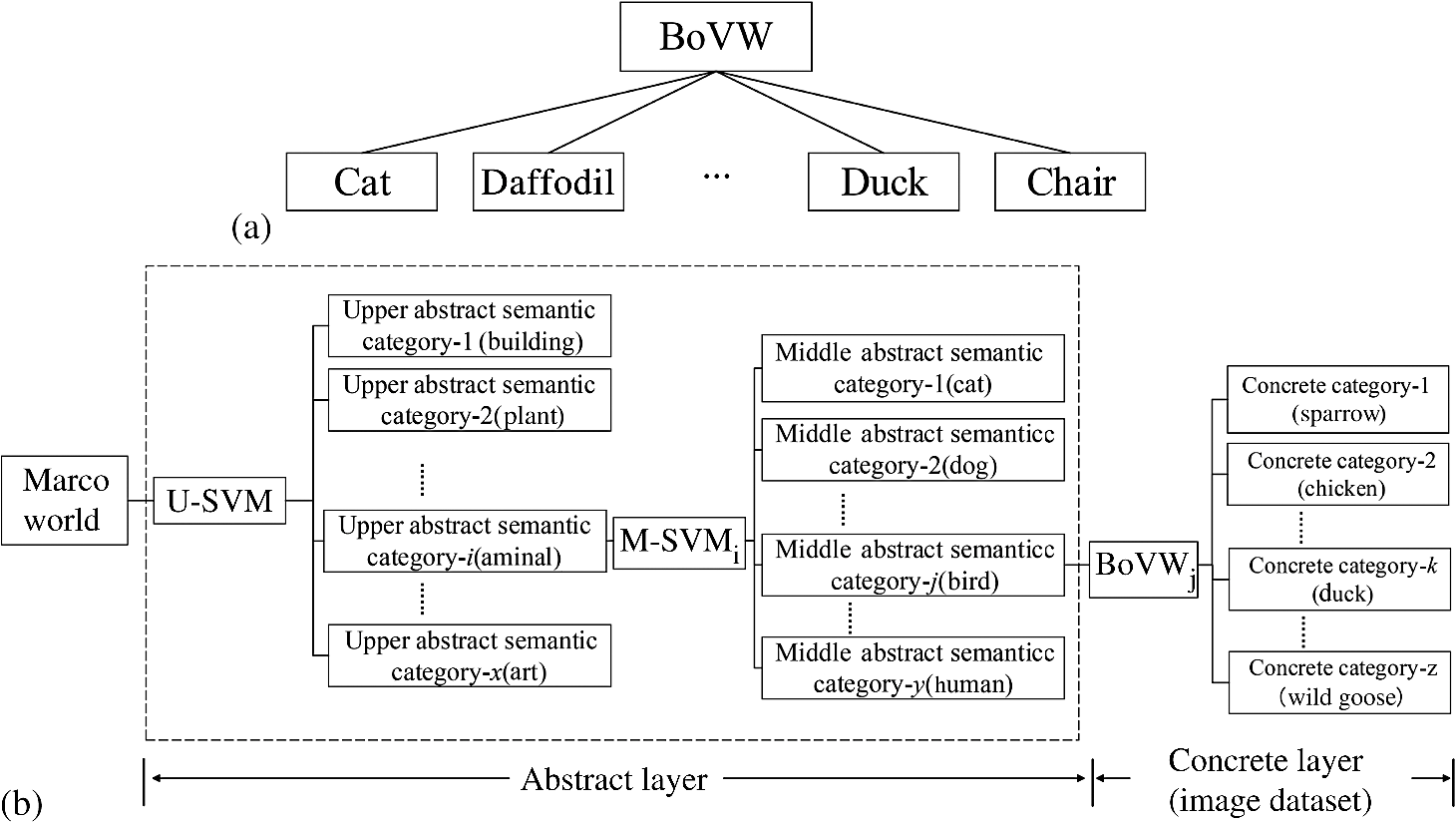 The whole process of MASL consists of two parts: bottom-up semantic classifier learning and top-down classification. In the learning process, each concrete classifier is first trained with concrete semantic visual vocabulary. Then abstract semantic classifiers including U-SVM and every M-SVMs will be trained. Learning is from bottom to top because the abstraction level rises from bottom to top. At the stage of classification, the inference of the category of a testing image is from top to bottom, reflecting the decrease in the level of abstraction. 3.2.1.Bottom-up semantic classifier learningThe purpose of bottom-up semantic learning is to train the semantic classifiers with a semantic visual vocabulary of corresponding layers.56 This process can be divided into three steps: first, each concrete classifier in Fig. 4(b) is trained by a visual semantic attribute (VSA) composed by semantic visual words from semantic preserving BoW (SPBoW).56 The input of from the concrete layer is images from data sets; then to train the middle abstract classifier of middle abstract semantic category (MASC), samples from every CC of the MASC are randomly selected with equal probability to ensure every category has the same chance of being selected to construct a visual vocabulary to improve the descriptive ability. The semantic visual vocabulary is generated from selected samples by SPBoW to train . The U-SVM classifier for the upper abstract semantic category (UASC) is trained in the same way to complete the learning process. 3.2.2.Top-down classificationFollowing completion of the bottom-up training stage, to find the category of an input image, UASC is first generated by U-SVM. Then the corresponding MASC is calculated by M-SVMs. Finally, the CC is concluded. The processes of classification are described as where and are the visual attributes of the ’th upper and ’th middle abstract categories, is the visual vocabulary, and is the measurement function utilized by classifiers. The visual semantic vocabulary is generated by SPBoW.Since the decision processes are sequential, if was incorrect, the remaining inference processes would be meaningless. Thus, we adopt a two-step verification strategy to decrease the dependence on upper layers and reduce error rates. First, the testing image is passed through U-SVM, then before the final decision is made, is passed to all M-SVMs for further verification. Let the output values of U-SVM and M-SVMs be and , respectively. The middle abstract category of the corresponding layer is finally decided by the following criterion: where and are the number of upper and middle classifiers, and and are the output values of ’th U-SVM and ’th M-SVM, respectively, , . At last, the traditional strategy of BoVW is utilized to get outputs , where is the number of categories under each classifier. Image is classified according to the following criterion:3.2.3.Summary of multilayer abstract semantics labelingCompared with original BoVW, the proposed model makes its improvement from the perspective of abstraction by introducing abstract semantic layers to narrow semantic gaps. Semantic visual vocabulary is utilized as a training feature and strategy to improve the performance of classifiers. The proposed learning algorithm is described in Algorithm 1, where , is the size of the codebook, is short for ’th CC, is the abbreviation of the ’th middle abstract category, is short for the ’th upper abstract category, SVVS stands for semantic visual vocabulary set, and is the number of CC under ’th MAC. is the generated visual words by SPBoW from under . Algorithm 1The learning process of MASL.
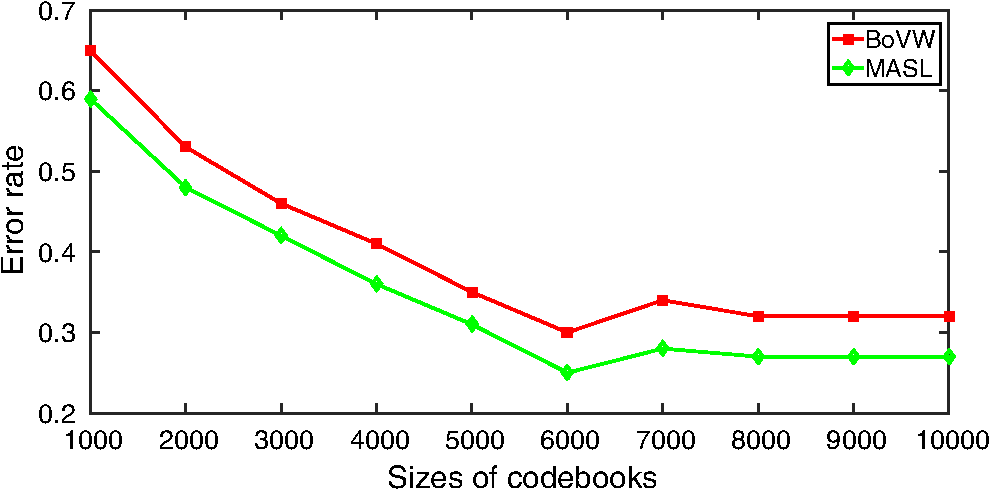
3.3.Summary of the Proposed Cognition-Based Hybrid Motivation FrameworkWe will summarize the general framework of CHM in Fig. 5 and Eq. (4). For every object in the scene, context information13 is utilized to assist in classification. Emp-Obj and NEmp-Obj represent the objects that frequently and infrequently occur in an indoor scene according to experience, respectively. According to the mechanism of cognition process described in Fig. 1, knowledge learned in EAI will be added to BEL to simulate the human learning process. Here, we are using an asterisk in the expression, representing an arbitrary number of objects.Fig. 5Learning and annotating processes of the proposed cognition-based hybrid motivation framework. First, the objects are detected by the method proposed by Hedau et al.28 After the modules are trained, images are labeled successively by experience- and assumption-based inference (EAI) and best-effort object labeling (BEL). To simulate the human inference process, the newly learned knowledge of objects in EAI will be added to BEL, including the category and corresponding classifiers.  4.Experiments and AnalysisIn this section, we will show the experimental results of MASL and CHM in the following subsections, including horizontal and vertical benchmarks, and semantic quantification. MASL is first tested on multiple data sets, and then utilized in CHM for indoor scene annotation. 4.1.Data Sets and Experimental SettingsThe proposed framework is validated on four popular data sets used in classification experiments. The details are listed below: The Caltech-101 data set57 contains 9197 images in 101 categories. The size of each image is roughly . The outline of each object is carefully annotated. For each category, at least 30 images are randomly selected for the learning process as described by Wang et al.,58 and the rest of the images are used as testing samples. The PASCAL VOC 2007 data set59 contains 9963 images in 20 object categories. There is a bounding box for each positive example of an object. Compared with Caltech-101, the data set is more difficult since the number of instances in an image is not always one. For Caltech-101 and PASCAL VOC 2007, we randomly select additional 10 images from each category to form a subset for vertical benchmarks described in Sec. 4.2. The Microsoft Research Cambridge (MSRC) data set60 contains 591 images in 23 object classes. Each image is labeled by pixels. The resolution of images is roughly . Two categories, “horse” and “mountain,” were removed from evaluation due to their small number of positive samples, as suggested in the description page of the data set. MSRC and Caltech-101 are used for horizontal benchmarks described in Sec. 4.3. For MSRC, images are equally divided for training and testing. The MIT indoor is a data set of 15,620 images over 67 indoor scenes.46 There are at least 100 images per category. Here, we follow the settings described by Quattoni and Torralba.46 The percentage of training and testing images of each category is 80% and 20%, respectively. All experiments were carried out on a workstation with quad-core 2.13 GHz CPU and 12 GB memory. 4.2.Experiment I: Vertical BenchmarksAs mentioned in the previous research,36 the performance of BoVW-based methods is affected by the size of visual vocabulary. In vertical benchmarks, self-evaluation of MASI and BoVW under different parameters is utilized to determine the optimized size of visual vocabularies. Testing images are from Caltech-10157 and PASCAL VOC 2007,59 as shown in Fig. 6, with results given in Fig. 7. We can see from the result that a larger size of codebook is actually beneficial for reducing the error rate, but does not mean a consistently better performance. Complex visual vocabulary lowers the performance, and this is consistent with the previous research.61 Meanwhile, the larger the codebook, the more computational cost is needed to build the visual vocabulary. Since the underlying techniques utilized by MASL are also based on BoVW, trends for both methods are similar. Compared with BoVW, the introduction of middle abstract layers in MASL leads to a better performance. Here, the size of visual vocabulary is set to 6000. 4.3.Experiment II: Horizontal BenchmarksIn this section of the experiments, we will compare MASL with other similar classification methods and then show the results of semantic gap quantification. 4.3.1.Comparison on classificationAs previously performed by Zhou et al.,62 several approaches62–64 are evaluated on selected data sets.35,63,65,66 Results are given in Fig. 8(a) and classification performances of individual classes for MASL are reported in detail through confusion tables in Figs. 8(b) and 8(c). Names of data sets are abbreviated according to their providers.62 Since OT65 and FP63 are part of the LS35 data set, we only give the confusion table for LS and LF66 (similar to Zhou et al.62) to show how the different categories are confused in Fig. 8. Fig. 8Classification results and corresponding confusion tables of selected data sets. (a) Comparison with other classification methods. (b) Confusion table for LS data set. (c) Confusion table for LF data set.  We can see from Fig. 8 that MASL achieves the best performance on all tests. This is because by introducing hierarchical semantics, the codebook generated by MASL is more discriminative and effective in reducing the semantic loss during codebook generation. From the confusion table shown in Fig. 8, we can see that although considerable confusion exists between man-made and natural scene categories (e.g., bedroom versus living room, kitchen versus living room), our MASL still outperforms other methods, including that of Zhou et al.,62 indicating the effectiveness of the proposed MASL classification method. 4.3.2.Semantic gap quantificationSemantic gap measurement described by Tang et al.,67 is utilized to quantify semantic gaps, which can be described as where represents the set of the nearest neighbors of in the visual space. Semantic distance between and each of its neighbors is measured by the cosine distance between the vectors of their tags. For MASL, semantic gap is quantified as where represents the image semantic gap between the concrete layer and MASC, and denotes the image semantic gap between MASC and UASC. To fully evaluate the semantic gaps of MASL, we constructed multiple semantic hierarchies for MSRC60 and Caltech-101,57 as shown in Figs. 9(a) and 9(b). Four abstract categories were constructed by selected 14 CCs with sufficient and unambiguous training/testing images. Experimental results are provided in Figs. 9(c) and 9(d). We can see that MASL was more effective in narrowing the semantic gap between concepts and visual data. For abstract categories with few CCs, the difference between BoVW and MASL was not significant. The performance of MASL was slightly better than that of BoVW. However, for larger abstract categories such as animal on Caltech-101, substantial improvement was observed (0.943 for BoVW versus 0.552 for MASL on Caltech-101; 0.829 for BoVW versus 0.773 for MASL on MSRC). This is because, when constructing visual data, the introduction of upper and middle abstract layers prevents interference from completely irrelevant categories. Conversely, when the scale of abstract category is small, the disturbance between each CC is relatively small, thus narrowing the semantic gap between the two methods is approximately coincident.4.4.Experiment III: Benchmarks on Scene AnnotationIn this experiment, we fully evaluate the overall performance of the proposed CHM framework on the MIT-indoor data set. Here, we initially define three basic objects for the indoor scene: table, chair, and bed, and the inference process is given in Similar to Quattoni and Torralba,46 the tests are divided into four parts containing different categories. Sample images are shown in Fig. 10.Fig. 10Sample images from MIT-indoor data set. As described by Quattoni and Torralba, the whole data set is divided into four parts: (a) P1, (b) P2, (c) P3, and (d) P4.46  The methods proposed by Hossein et al.68 and Gong et al.69 are based on a convolutional neural network (CNN). CNNs have become prominent in machine learning during the past decade due to their highly effective performance. Optimized parameters are set for each method, and a CNN is implemented by EBLearn.70 To compare methods fairly across different applications, the performance of all methods is evaluated by the precision of classification on both manually labeled and automatically detected28 objects in the data set. The results of average performances are given in Table 1. We can conclude that our CHM framework achieves a comparable performance with other methods. Both EAI and contextual information play important roles in boosting the performance of the framework and CHM outperforms other annotation methods71–73 on all tests. Although CHM does not outperform CNN-based methods on the second and fourth tests, the performance gaps between them are not remarkable. Meanwhile, CHM outperforms the CNN-based methods on the first and third tests, and the average performance of CHM is better than all classification methods, proving its effectiveness, as most samples contain objects that fit the category definition well, given by Eq. (8). In the second and fourth tests, two CNN-based methods, respectively, achieved better performance, as differences between categories are relatively small, i.e., the testing sets are more confusing for other methods. The structural advantage of CNN, with multiple layers and neurons, ensures that CNN-based methods achieve a better performance in this situation. Table 1Comparison of results between CHM and other methods on MIT-indoor data set.46 The data set is divided into four groups for detailed tests.
A sample of the object detection and categorization results is shown in Fig. 11. Figures 11(a)–11(d) show the correct object detection and categorization results of indoor scene categories. We can see from Figs. 11(b) and 11(d) that the CHM framework deals with empirical and out-of-experience objects properly, showing self-adaption under the above assumption; Figs. 11(a) and 11(c) show the detection of the empirical objects we set; Fig. 11(b) shows the importance of environment context. When the empirical objects are detected [a table in Fig. 11(b)], objects around it are considered as out-of-experience objects and will be categorized by BEL. Figures 11(e) and 11(f) show the importance of EAI. With a table first detected, the object above would then be categorized as a chandelier according to context. All the results prove that our framework is useful for scene annotation. Error examples are also shown. Figure 11(g) shows that some objects are incorrectly classified; in this case, the chest is classified as a chair. Figure 11(h) shows error detection results from the detection module. The chair and chest are detected with the table so that the whole object is classified as a table. Figure 11(i) shows both misdetection and misclassification. A shelf and table are detected as one object and classified as a chest. From these incorrect results, we can conclude that current object detection methods28 remain unable to precisely restore the original 3-D structure for some situations, such as for low-resolution images with indistinct 3-D structure, and this needs further investigation. Additionally, much work still needs to be done to improve the performance of MASL. The purpose of our study was to simulate the scene annotation process of humans to make the annotation process more appropriate and human-like. Although the improvement of the performance is not remarkable compared with existing methods, our work provides yet another method for indoor scene annotation, and a preliminary investigation into knowledge-based scene understanding by means of rule inference constructed from annotated objects. Differing from traditional image annotation methods, our method is bio-inspired, introducing cognitive models and inference rules to simulate the annotating process of humans. Our proposed CHM framework, as evidenced by the results shown in Table 1, outperforms the methods proposed by Wang et al.71, Tsai et al.,72 and Xie et al.73 on all tests. In general, CHM performs better than CNN-based methods,68,69 which are the state-of-the-art results. The performance of CHM is influenced by existing classification algorithms. Object classification methods based on BoVW have achieved significant improvement over the last few years; however, there remains significant room for improvement. Compared with the object detection and learning skills of humans, existing algorithms in computer vision are still far from satisfactory. The progressive experimental results of classification, semantic gap quantification, and scene annotation have proven the effectiveness of the proposed MASL classification method and CHM scene annotation framework from multiple perspectives. Although far from perfect, the CHM annotation framework demonstrates the possibility of scene annotation combining cognition theory and computer vision. Finally, due to the modular design of our framework, its performance will improve with the development of existing object detection and recognition methods. 5.ConclusionIn this work, we address the scene annotation problem and propose a framework to simulate the human cognitive process. Compared with the previous works, our experimental results have proven the effectiveness of our framework on both narrowing semantic gaps and boosting the performance of classification. However, limitations remain and, although the performance of CHM is comparable with state-of-the-art methods, improvement is still required. We believe that the performance of CHM will improve with the development of object classification algorithms, due to its modular design. Following this preliminary study on indoor scene annotation, future research will target the interpretation of an indoor scene based on the annotated objects. AcknowledgmentsThis research was supported by the National Science Foundation of China (Grant Nos. 61171184 and 61201309). ReferencesD. Zhang, M. M. Islam and G. Lu,
“A review on automatic image annotation techniques,”
Pattern Recognit., 45
(1), 346
–362
(2012). http://dx.doi.org/10.1016/j.patcog.2011.05.013 PTNRA8 0031-3203 Google Scholar
S. Z. Li, Markov Random Field Modeling in Image Analysis, Springer Science & Business Media, London
(2009). Google Scholar
C. Wang, N. Komodakis and N. Paragios,
“Markov random field modeling, inference & learning in computer vision & image understanding: a survey,”
Comput. Vision Image Understanding, 117
(11), 1610
–1627
(2013). http://dx.doi.org/10.1016/j.cviu.2013.07.004 CVIUF4 1077-3142 Google Scholar
X. He, R. S. Zemel and M. Carreira-Perpindn,
“Multiscale conditional random fields for image labeling,”
in Proc. of the 2004 IEEE Computer Society Conf. on Computer Vision and Pattern Recognition (CVPR 2004),
II-695
(2004). Google Scholar
S. Gould et al.,
“Multi-class segmentation with relative location prior,”
Int. J. Comput. Vision, 80
(3), 300
–316
(2008). http://dx.doi.org/10.1007/s11263-008-0140-x IJCVEQ 0920-5691 Google Scholar
N. Payet and S. Todorovic,
“Hough forest random field for object recognition and segmentation,”
IEEE Trans. Pattern Anal. Mach. Intell., 35
(5), 1066
–1079
(2013). http://dx.doi.org/10.1109/TPAMI.2012.194 Google Scholar
B. T. C. G. D. Roller,
“Max-margin Markov networks,”
Adv. Neural Inf. Process. Syst., 16 25
(2003). 1049-5258 Google Scholar
J. Fan et al.,
“Structured max-margin learning for inter-related classifier training and multilabel image annotation,”
IEEE Trans. Image Process., 20
(3), 837
–854
(2011). http://dx.doi.org/10.1109/TIP.2010.2073476 IMGSBL Google Scholar
W. Zhang et al.,
“Multi-kernel multi-label learning with max-margin concept network,”
in IJCAI Proc. Int. Joint Conf. on Artificial Intelligence,
1615
(2011). Google Scholar
R. Mottaghi et al.,
“Analyzing semantic segmentation using hybrid human-machine CRFs,”
in 2013 IEEE Conf. on Computer Vision and Pattern Recognition (CVPR),
3143
–3150
(2013). Google Scholar
C. Galleguillos, A. Rabinovich and S. Belongie,
“Object categorization using co-occurrence, location and appearance,”
in IEEE Conf. on Computer Vision and Pattern Recognition (CVPR 2008),
1
–8
(2008). Google Scholar
L. Ladicky et al.,
“Graph cut based inference with co-occurrence statistics,”
in Computer Vision-ECCV 2010,
239
–253
(2010). Google Scholar
M. J. Choi, A. Torralba and A. S. Willsky,
“Context models and out-of-context objects,”
Pattern Recognit. Lett., 33
(7), 853
–862
(2012). http://dx.doi.org/10.1016/j.patrec.2011.12.004 PRLEDG 0167-8655 Google Scholar
Y. Jiang, H. Koppula and A. Saxena,
“Hallucinated humans as the hidden context for labeling 3D scenes,”
in 2013 IEEE Conf. on Computer Vision and Pattern Recognition (CVPR),
2993
–3000
(2013). Google Scholar
O. Blomberg,
“Conceptions of cognition for cognitive engineering,”
Int. J. Aviat. Psychol., 21
(1), 85
–104
(2011). http://dx.doi.org/10.1080/10508414.2011.537561 Google Scholar
T. Tang and H. Qiao,
“Improving invariance in visual classification with biologically inspired mechanism,”
Neurocomputing, 133 328
–341
(2014). http://dx.doi.org/10.1016/j.neucom.2013.11.003 NRCGEO 0925-2312 Google Scholar
J. M. Coughlan and A. L. Yuille,
“The Manhattan world assumption: regularities in scene statistics which enable Bayesian inference,”
in NIPS,
845
–851
(2000). Google Scholar
A. Saxena, M. Sun and A. Y. Ng,
“Learning 3-D scene structure from a single still image,”
in IEEE 11th Int. Conf. on Computer Vision, 2007 (ICCV 2007),
1
–8
(2007). Google Scholar
V. Hedau, D. Hoiem and D. Forsyth,
“Recovering the spatial layout of cluttered rooms,”
in IEEE 12th Int. Conf. on Computer vision,
1849
–1856
(2009). Google Scholar
G. Tsai et al.,
“Real-time indoor scene understanding using Bayesian filtering with motion cues,”
in 2011 IEEE Int. Conf. on Computer Vision (ICCV),
121
–128
(2011). Google Scholar
A. G. Schwing et al.,
“Efficient structured prediction for 3D indoor scene understanding,”
in 2012 IEEE Conf. on Computer Vision and Pattern Recognition (CVPR),
2815
–2822
(2012). Google Scholar
V. Hedau, D. Hoiem and D. Forsyth,
“Recovering free space of indoor scenes from a single image,”
in 2012 IEEE Conf. on Computer Vision and Pattern Recognition (CVPR),
2807
–2814
(2012). Google Scholar
H. Wang, S. Gould and D. Roller,
“Discriminative learning with latent variables for cluttered indoor scene understanding,”
Commun. ACM, 56
(4), 92
–99
(2013). http://dx.doi.org/10.1145/2436256.2436276 CACMA2 0001-0782 Google Scholar
S. Ramalingam et al.,
“Manhattan junction catalogue for spatial reasoning of indoor scenes,”
in 2013 IEEE Conf. on Computer Vision and Pattern Recognition (CVPR),
3065
–3072
(2013). Google Scholar
T. Shao et al.,
“An interactive approach to semantic modeling of indoor scenes with an RGBD camera,”
ACM Trans. Graph., 31
(6), 136
(2012). http://dx.doi.org/10.1145/2366145.2366155 ATGRDF 0730-0301 Google Scholar
X. Ren, L. Bo and D. Fox,
“RGB-(D) scene labeling: features and algorithms,”
in 2012 IEEE Conf. on Computer Vision and Pattern Recognition (CVPR),
2759
–2766
(2012). Google Scholar
J. P. Valentin et al.,
“Mesh based semantic modelling for indoor and outdoor scenes,”
in 2013 IEEE Conf. on Computer Vision and Pattern Recognition (CVPR),
2067
–2074
(2013). Google Scholar
V. Hedau, D. Hoiem and D. Forsyth,
“Thinking inside the box: using appearance models and context based on room geometry,”
in Computer Vision-ECCV 2010,
224
–237
(2010). Google Scholar
M. Wang, X. Liu and X. Wu,
“Visual classification by l1-hypergraph modeling,”
IEEE Trans. Knowl. Data Eng., 27 2564
–2574
(2015). http://dx.doi.org/10.1109/TKDE.2015.2415497 Google Scholar
M. Wang et al.,
“Unified video annotation via multigraph learning,”
IEEE Trans. Circuits Syst. Video Technol., 19 733
–746
(2009). http://dx.doi.org/10.1109/TCSVT.2009.2017400 Google Scholar
J. Yu, D. Tao and M. Wang,
“Adaptive hypergraph learning and its application in image classification,”
IEEE Trans. Image Process., 21 3262
–3272
(2012). http://dx.doi.org/10.1109/TIP.2012.2190083 IMGSBL Google Scholar
R. Hong et al.,
“Image annotation by multiple-instance learning with discriminative feature mapping and selection,”
IEEE Trans. Cybern., 44 669
–680
(2014). http://dx.doi.org/10.1109/TCYB.2013.2265601 CYBNAW 0011-4235 Google Scholar
G. Csurka et al.,
“Visual categorization with bags of keypoints,”
in Workshop on Statistical Learning in Computer Vision ECCV,
1
–2
(2004). Google Scholar
M. Varma and A. Zisserman,
“A statistical approach to texture classification from single images,”
Int. J. Comput. Vision, 62
(1–2), 61
–81
(2005). http://dx.doi.org/10.1007/s11263-005-4635-4 IJCVEQ 0920-5691 Google Scholar
S. Lazebnik, C. Schmid and J. Ponce,
“Beyond bags of features: spatial pyramid matching for recognizing natural scene categories,”
in 2006 IEEE Computer Society Conf. on Computer Vision and Pattern Recognition,
2169
–2178
(2006). Google Scholar
J. C. Van Gemert et al.,
“Comparing compact codebooks for visual categorization,”
Comput. Vision Image Understanding, 114
(4), 450
–462
(2010). http://dx.doi.org/10.1016/j.cviu.2009.08.004 CVIUF4 1077-3142 Google Scholar
R. Bahmanyar and M. Datcu,
“Measuring the semantic gap based on a communication channel model,”
in 2013 20th IEEE Int. Conf. on Image Processing (ICIP),
4377
–4381
(2013). Google Scholar
R. Du et al.,
“Object categorization based on a supervised mean shift algorithm,”
in Workshops and Demonstrations Computer Vision-ECCV 2012,
611
–614
(2012). Google Scholar
J. Snchez, F. Perronnin and T. De Campos,
“Modeling the spatial layout of images beyond spatial pyramids,”
Pattern Recognit. Lett., 33
(16), 2216
–2223
(2012). http://dx.doi.org/10.1016/j.patrec.2012.07.019 PRLEDG 0167-8655 Google Scholar
J. C. van Gemert et al.,
“Visual word ambiguity,”
IEEE Trans. Pattern Anal. Mach. Intell., 32
(7), 1271
–1283
(2010). http://dx.doi.org/10.1109/TPAMI.2009.132 Google Scholar
L. Xie et al.,
“Spatial pooling of heterogeneous features for image classification,”
IEEE Trans. Image Process., 23 1994
–2008
(2014). http://dx.doi.org/10.1109/TIP.2014.2310117 IMAPEJ Google Scholar
J. Liu, Y. Yang and M. Shah,
“Learning semantic visual vocabularies using diffusion distance,”
in IEEE Conf. on Computer Vision and Pattern Recognition (CVPR 2009),
461
–468
(2009). Google Scholar
B. Fernando et al.,
“Supervised learning of Gaussian mixture models for visual vocabulary generation,”
Pattern Recognit., 45
(2), 897
–907
(2012). http://dx.doi.org/10.1016/j.patcog.2011.07.021 PTNRA8 0031-3203 Google Scholar
R. Sternberg, Cognitive Psychology, Wadsworth Publishing, Boston
(2011). Google Scholar
J. Porway, Q. Wang and S. C. Zhu,
“A hierarchical and contextual model for aerial image parsing,”
Int. J. Comput. Vision, 88
(2), 254
–283
(2010). http://dx.doi.org/10.1007/s11263-009-0306-1 IJCVEQ 0920-5691 Google Scholar
A. Quattoni and A. Torralba,
“Recognizing indoor scenes,”
in IEEE Conf. on Computer Vision and Pattern Recognition (CVPR 2009),
413
–420
(2009). Google Scholar
S. Gupta et al.,
“Indoor scene understanding with RGB-D images: bottom-up segmentation, object detection and semantic segmentation,”
Int. J. Comput. Vision, 112
(2), 133
–149
(2015). http://dx.doi.org/10.1007/s11263-014-0777-6 IJCVEQ 0920-5691 Google Scholar
X. Li and Y. Guo,
“Multi-level adaptive active learning for scene classification,”
Lect. Notes Comput. Sci., 8695 234
–249
(2014). http://dx.doi.org/10.1007/978-3-319-10584-0_16 Google Scholar
M. Zang et al.,
“A novel topic feature for image scene classification,”
Neurocomputing, 148 467
–476
(2015). http://dx.doi.org/10.1016/j.neucom.2014.07.018 NRCGEO 0925-2312 Google Scholar
Z. Zuo et al.,
“Learning discriminative and shareable features for scene classification,”
Lect. Notes Comput. Sci., 8689 552
–568
(2014). http://dx.doi.org/10.1007/978-3-319-10590-1_36 Google Scholar
J. Luo, A. E. Savakis and A. Singhal,
“A Bayesian network-based framework for semantic image understanding,”
Pattern Recognit., 38
(6), 919
–934
(2005). http://dx.doi.org/10.1016/j.patcog.2004.11.001 PTNRA8 0031-3203 Google Scholar
H. Bannour and C. Hudelot,
“Building semantic hierarchies faithful to image semantics,”
Lect. Notes Comput. Sci., 7131 4
–15
(2012). http://dx.doi.org/10.1007/978-3-642-27355-1_4 Google Scholar
M. Marszalek and C. Schmid,
“Semantic hierarchies for visual object recognition,”
in IEEE Conf. on Computer Vision and Pattern Recognition (CVPR 07),
1
–7
(2007). Google Scholar
G. Griffin and P. Perona,
“Learning and using taxonomies for fast visual categorization,”
in IEEE Conf. on Computer Vision and Pattern Recognition (CVPR 2008),
1
–8
(2008). Google Scholar
L. Li-Jia et al.,
“Building and using a semantic visual image hierarchy,”
in 2010 IEEE Conf. on Computer Vision and Pattern Recognition (CVPR),
3336
–3343
(2010). Google Scholar
L. Wu, S. C. Hoi and N. Yu,
“Semantics-preserving bag-of-words models and applications,”
IEEE Trans. Image Process., 19
(7), 1908
–1920
(2010). http://dx.doi.org/10.1109/TIP.2010.2045169 Google Scholar
L. Fei-Fei, R. Fergus and P. Perona,
“Learning generative visual models from few training examples: an incremental Bayesian approach tested on 101 object categories,”
Comput. Vision Image Understanding, 106
(1), 59
–70
(2007). http://dx.doi.org/10.1016/j.cviu.2005.09.012 CVIUF4 1077-3142 Google Scholar
J. Wang et al.,
“Locality-constrained linear coding for image classification,”
in 2010 IEEE Conf. on Computer Vision and Pattern Recognition (CVPR),
3360
–3367
(2010). Google Scholar
M. Everingham et al.,
“The pascal visual object classes (VOC) challenge,”
Int. J. Comput. Vision, 88
(2), 303
–338
(2010). http://dx.doi.org/10.1007/s11263-009-0275-4 IJCVEQ 0920-5691 Google Scholar
S. Savarese, J. Winn and A. Criminisi,
“Discriminative object class models of appearance and shape by correlations,”
in 2006 IEEE Computer Society Conf. on Computer Vision and Pattern Recognition,
2033
–2040
(2006). Google Scholar
A. Bosch, A. Zisserman and X. Munoz,
“Scene classification via plsa,”
in Computer Vision-ECCV 2006,
517
–530
(2006). Google Scholar
L. Zhou, Z. Zhou and D. Hu,
“Scene classification using a multi-resolution bag-of-features model,”
Pattern Recognit., 46
(1), 424
–433
(2013). http://dx.doi.org/10.1016/j.patcog.2012.07.017 PTNRA8 0031-3203 Google Scholar
L. Fei-Fei and P. Perona,
“A Bayesian hierarchical model for learning natural scene categories,”
in IEEE Computer Society Conf. on Computer Vision and Pattern Recognition (CVPR 2005),
524
–531
(2005). Google Scholar
H. Nakayama, T. Harada and Y. Kuniyoshi,
“Global Gaussian approach for scene categorization using information geometry,”
in 2010 IEEE Conf. on Computer Vision and Pattern Recognition (CVPR),
2336
–2343
(2010). Google Scholar
A. Oliva and A. Torralba,
“Modeling the shape of the scene: a holistic representation of the spatial envelope,”
Int. J. Comput. Vision, 42
(3), 145
–175
(2001). http://dx.doi.org/10.1023/A:1011139631724 IJCVEQ 0920-5691 Google Scholar
L.-J. Li and L. Fei-Fei,
“What, where and who? Classifying events by scene and object recognition,”
in IEEE 11th Int. Conf. on Computer Vision (ICCV 2007),
1
–8
(2007). Google Scholar
J. Tang et al.,
“Semantic-gap-oriented active learning for multi-label image annotation semantic-gap-oriented active learning for multi label image annotation,”
IEEE Trans. Image Process., 21
(4), 2354
–2360
(2012). http://dx.doi.org/10.1109/TIP.2011.2180916 Google Scholar
A. Hossein et al.,
“From generic to specific deep representations for visual recognition,”
in 2015 IEEE Conf. on Computer Vision and Pattern Recognition Workshops (CVPRW),
(2015). Google Scholar
Y. Gong et al.,
“Multi-scale orderless pooling of deep convolutional activation features,”
in Computer Vision-ECCV 2014,
392
–407
(2014). Google Scholar
P. Sermanet, K. Kavukcuoglu and Y. LeCun,
“Eblearn: open-source energy-based learning in C++,”
in 21st Int. Conf. on Tools with Artificial Intelligence (ICTAI’09),
693
–697
(2009). Google Scholar
X. J. Wang et al.,
“Annotating images by mining image search results,”
IEEE Trans. Pattern Anal. Mach. Intell., 30
(11), 1919
–1932
(2008). http://dx.doi.org/10.1109/TPAMI.2008.127 Google Scholar
D. Tsai et al.,
“Large-scale image annotation using visual synset,”
in 2011 IEEE Int. Conf. on Computer Vision (ICCV),
611
–618
(2011). Google Scholar
L. Xie et al.,
“Orientational pyramid matching for recognizing indoor scenes,”
in 2014 IEEE Conf. on Computer Vision and Pattern Recognition (CVPR),
3734
–3741
(2014). Google Scholar
BiographyZhipeng Ye is a PhD candidate at the School of Computer Science and Technology, Harbin Institute of Technology (HIT). He received his master’s degree in computer application technology from Harbin Institute of Technology in 2013. His research interests cover image processing and machine learning. Peng Liu is an associate professor at the School of Computer Science and Technology, HIT. He received his doctoral degree in microelectronics and solid-state electronics from HIT in 2007. His research interests cover image processing, video processing, pattern recognition, and design of very large scale integration circuit. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||