
|
|
1.IntroductionFace recognition has received substantial attention for a long time. Many typical methods have been proposed to perform face recognition.1–4 Since Wright et al. presented the sparse representation-based classification (SRC) method,5 it has been widely studied in many pattern recognition applications due to its promising results, such as face recognition,6,7 along with gender,8 digit,9,10 biology data,11,12 and medical image13,14 classification. Although many improved SRC-based methods have been proposed for robust face recognition,15–19 most of them require rigid image alignment, where all images of an object or objects of interest are aligned to a fixed canonical template. Until now, much work has been performed to address the alignment problem.20,21 However, such alignment is still difficult to achieve in real scenarios, such as partial face, scale, or pose variation face recognition. To address the alignment problem in SRC, some methods22,23,24 introduced the scale-invariant feature transform (SIFT)22 or the speeded-up robust features25 descriptor to the recognition method. However, most of these methods pay little attention to the correlation among the query descriptors, which is found to be useful for classification. Thus, it is necessary to study a method exploiting the correlation of the query descriptors for robust alignment-free face recognition, which is the focus of this paper. Supposing that one image is represented with a set of SIFT descriptors22 which are robust to handle scale variations and rotation, the SIFT-based method can solve the problem of alignment. The simple matching method22 obtains the identification for each query descriptor separately according to the best matching. By voting with the separate results, the final identification is determined. Rather than matching, Liao and Jain presented a multikeypoint descriptors-based SRC (MKD-SRC) method.23 The method solves the sparse representation (SR) problem for each query descriptor separately and determines the image identification using all of the reconstruction residuals. By exploring the discrimination of the atoms in a SIFT dictionary, Sun et al. proposed a clustering-weighted SIFT-based classification method via SR24 and obtained better robustness for alignment-free face recognition with sufficient samples. After analyzing these methods, we find that the above-described methods treat each query descriptor independently and equally. For each query descriptor, there may be some similar atoms distributing in different classes in the dictionary, which will influence the classification performance.24 Therefore, if we solve the SR problem for each descriptor extracted from a query image separately, some false identities may be obtained, resulting in errors in the final image classification. As a result, it is beneficial to solve the SR problem simultaneously for all query descriptors by their correlation. To handle this problem, the concept of the joint sparse representation (JSR) is introduced. In this paper, we propose a weighted joint sparse representation-based classification (WJSRC) method. There are three contributions in our work. (1) For exploration of the correlation among query descriptors, the concept of JSR is introduced. (2) Considering the reliability of the query descriptors, a modified JSR model with a weighted sparsity constraint is introduced. (3) A WJSRC algorithm is proposed to solve the modified model. Because the proposed method studies the correlation among the query descriptors and their own reliability, the performance of the alignment-free recognition is improved. The remainder of this paper is organized as follows. In Sec. 2, we review the JSR algorithm. Section 3 proposes the WJSRC method. The experimental results using the proposed method on the Yale database,26 the Olivetti Research Laboratory database,27 and the AR database (The AR database is a public face database created by Aleix Martneza and Robert Benavente.)28 are described in Sec. 4. The conclusions are presented in Sec. 5. 2.Joint Sparse RepresentationThe original SRC method5 solves the SR problem for query descriptors separately. To explore the correlation among the query descriptors, the JSR is introduced. As far as we know, there are two types of JSR methods. (1) The first group of JSR methods utilizes multiple types of keypoint features and dictionaries.29–31 If we extract the shape, color, and texture features from a face image, which are different from each other, it is necessary to construct a single dictionary for each type of feature. Thus, three dictionaries are obtained. For a test image, multiple types of query descriptors should be extracted, each of which can be just sparsely represented by its corresponding dictionary. However, the SR for all query descriptors should be performed under the JSR constraint. The workflow is shown in Fig. 1(a). (2) The second group of JSR methods utilizes multiple keypoint features and a single dictionary,32–34 whose workflow is shown in Fig. 1(b). This method supposes that multiview sample images for an object are obtained, and the queries of the object are also multiview images. With the same type of features, a single dictionary is constructed. Because the query images are similar, just one atom is selected from the dictionary to represent them at each iteration step of the atom selection process. After adequate iteration, one set of features from the dictionary can be selected to represent all query images simultaneously under the joint representation constraint.34 Thus, the sparse coefficients share the same sparsity pattern at the atom level,34 but the coefficient value is different, which is illustrated in Fig. 2(b). This method is different from the original SRC,5 which solves the SR problem for each view image separately. The sparse coefficients’ sparsity and value in the SRC method are different from each other, which are depicted in Fig. 2(a). In real scenarios, the multiview images of an object may not be well represented by the same features. In Refs. 32 and 33, Zhang et al. optimized it by proposing a joint dynamic sparse representation (JDSR) method, which chooses different features from the same class to represent each view image at each iteration step of the atom selection process. The sparse coefficients share the same sparsity pattern at the class level, but not at the atom level, which is depicted in Fig. 2(c). Fig. 1The workflows of the two types of joint sparse representation methods. (a) The workflow of the multiple types of features and dictionaries-based JSR method. (b) The workflow of the multiple features and single dictionary-based JSR method.  Fig. 2The sparsity pattern of multiple task sparse representation,23 joint sparse representation34 and joint dynamic sparse representation.33 Each column vector denotes a coefficient vector and each block denotes a coefficient value. The white block denotes a zero value and others denote different nonzero values. (a) Multiple task sparse representation. It solves the SR problem for each query feature separately. The coefficient sparsity and value of each query feature may be different. (b) Joint sparse representation. Sparse coefficients share the same sparsity pattern at atom level, i.e., selecting the same atoms for all query vectors simultaneously, but with different coefficient values. (c) Joint dynamic sparse representation. The atoms on the same arrow line represent one set of features selected at each iteration step of the atom selection process. From one iteration to the next iteration, the algorithm keeps the existing atoms in the set and tries to find the next best atoms to add to the set. Sparse coefficients share the same sparsity pattern at class-level. 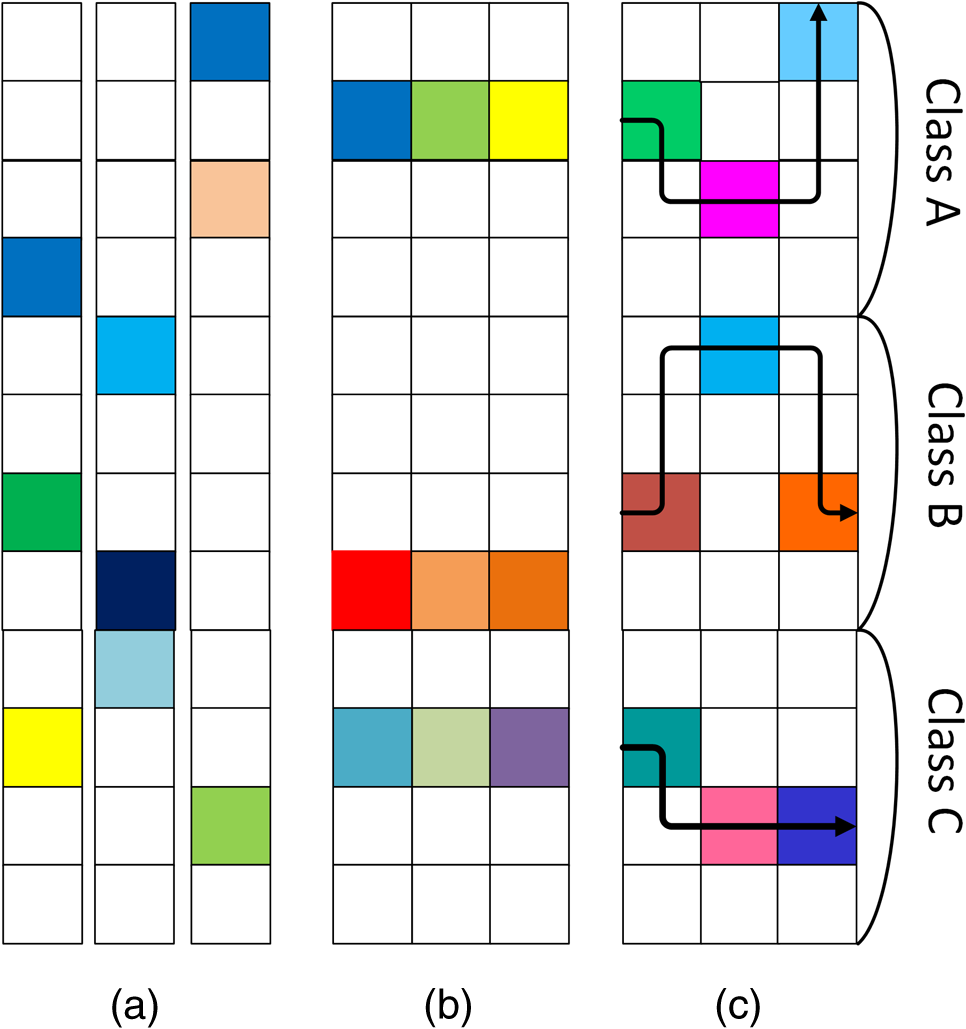 Although the problem of face recognition with SIFT descriptors belongs to the second type, the existing methods cannot solve it perfectly for three reasons. (1) The query descriptors are quite different from each other, for example, the descriptors extracted from an eye are different from those of a mouth, which is obviously different from the characteristic of the query features in Refs. 32 to 34. (2) The number of query descriptors is often large, typically in the hundreds; as a result, the query descriptors are challenging to join. (3) Not all of the query descriptors contain correct identity information in practice. For example, the descriptors extracted from the occluded module cannot be treated equally to those from the clear module. The unreliable descriptors will mislead the JSR, which has been verified by experiments in Ref. 32. As a result, a more robust method is required to solve our problem. 3.Proposed MethodGiven samples collected from classes, the SIFT descriptors extracted from the samples of the ’th class constructed the ’th sub-dictionary , where denotes the quantity of the descriptors of the ’th class, and is the SIFT descriptor. All of the sub-dictionaries are pooled together to construct the dictionary , where denotes the quantity of descriptors in all classes. Given a query image , it can be represented by a set of SIFT descriptors, i.e., , where is called a query descriptor. 3.1.WJSR ModelIf a query image belongs to one of the given classes, then the query descriptors extracted from it can be well represented by the ones of the corresponding class. Because the SIFT descriptors are discriminative, for example, the descriptors of an eye are different from those of a mouth, they should be represented by different atoms of the same class, i.e., the sparse coefficients share the same sparsity pattern at the class level32,33 but not at the atom level.34 As mentioned above, the query descriptors should not be treated equally. Thus, we proposed a model of WJSR, whose mathematical model is where and denote -norm and -norm, respectively, is the sparsity, and is the weight for the classification reliability of the ’th query descriptor. Supposing the coefficients matrix and the nonzero coefficients of the selected atoms matrix represents the ’th selected set, the atoms of which belong to the same class, and is a matrix constraint term enabling the sparse coefficients to be in line with the weighted joint sparsity pattern. In Eq. (1), is not only a measurement of the reliability for the ’th query descriptor but also a balance factor for the residuals. To obtain the whole minimal residuals, we must make the residuals of the larger weight query descriptors smaller, i.e., the representation of the more reliable descriptors must be a more accurate approximation because they contain the correct classification information. Thus, in Algorithm 1, the reliable query descriptors lead the atoms’ selection.Algorithm 1The weighted joint sparse representation based classification (WJSRC).
3.2.WJSR-Based Classification Algorithm3.2.1.Calculating the weight for each query descriptorFor classification, not all query descriptors contribute equally. In this paper, we measure the importance of each query descriptor by the similarity between the query descriptor and the dictionary , i.e., , and then the weight of can be defined as where , and is the least similarity value. Then we can construct the weight vector as .3.2.2.Solving the WJSR problemSolving Eq. (1) is an NP-hard problem due to the mixed-norm minimization with a weighted joint sparsity constraint. In this paper, we propose a greedy algorithm, i.e., the WJSRC algorithm, to solve this problem, which is described in detail in Algorithm 1. The algorithm is similar to the orthogonal matching pursuit algorithm,35 with a major difference in the atom selection criteria. In the WJSRC algorithm, the most relevant set of atoms belonging to the same class is selected at each iteration step in the atom selection process. To minimize the whole residuals, we propose the weighted atoms selection criteria, which is automatically led by the larger weight descriptors. 3.3.SummaryThe proposed WJSRC method is summarized as follows:
Determine the identity of the query image using Eq. (3). 4.ExperimentsIn this section, we present the performance of the “proposed method” on three public databases: (1) the Yale database,26 (2) the Olivetti Research Laboratory (ORL) database,27 and (3) the AR database.28 We focus on three scenarios of alignment-free face recognition: (1) arbitrary patches of holistic faces; (2) faces with arbitrary pose and expression variations; and (3) faces with occlusions. A performance comparison among the related methods, namely the SIFT matching,22 MKD-SRC,23 CWS-SRC,24 JDSRC,33 and the original SRC methods,5 is conducted. The three experiments are performed on gray images. The SIFT descriptors extracted from images are of dimension 128. 4.1.Determination of the ParametersIn the experiments, one parameter should be set manually, i.e., the sparsity , which is the number of iterations in Algorithm 1. At each iteration step in the atom selection process, one set of descriptors is selected to represent the query descriptors. Therefore, with the increase in , the representation for most of the query descriptors becomes more approximate. To ascertain the relationship between the recognition performance and the sparsity , we examined different values of on the ORL database and evaluated the resulting performance in terms of the accuracy. The curve is depicted in Fig. 3, which shows that when is greater than 7, the recognition accuracy is stable, i.e., the approximation is adequate. Therefore, is set as 7, which has been proven to also be suitable for other databases. 4.2.Partial Face Recognition with an Arbitrary PatchThis experiment is conducted on the Yale database, which consists of 165 frontal face images of 15 subjects with an image size of . Two, three and four images (per subject) are randomly selected as samples. From each of the remaining images in the three settings, one patch of random size at a random position is cropped as a query, where and are randomly selected from (100,160) and (80,110). The queries are all partial faces. Some examples of the sample and query images are shown in Fig. 4. Fig. 4Some examples of the sample and partial query images. (a) The examples of partial query images. (b) The examples of the sample images.  For each experimental setting, we use 10 random splits of the data in the experiment. The average results are presented in Table 1. Because the original SRC method is not suitable in this scenario, the other five algorithms are compared. The descriptors extracted from a query partial face are relatively insufficient, and the classification information is limited. Thus, it is necessary to join all of the query descriptors by their correlation. The results in Table 1 show that the WJSRC method achieves the highest recognition rate in the three settings, which indicates the validity and advantage of the proposed method in the scenario of incomplete classification information. Table 1The average recognition performance of the partial faces.
4.3.Face Recognition with Pose and Expression VariationThis experiment is conducted on the ORL database, which contains 400 images of 40 subjects with different expressions, frontal poses, and slight scale variations. We randomly selected two, three, four, and five images from each subject as samples and the remaining as queries. Some examples of the sample and query images are shown in Fig. 5. For each experimental setting, we use 10 random splits of the data in the experiment. The average results are presented in Table 2. Fig. 5Some examples of the sample and query images. (a) The examples of the sample images. (b) The examples of the query images.  Table 2The average recognition performance on the ORL database.
In this experiment, the recognition rate of the proposed WJSRC method is found to be outstanding. The original SRC method does not work ideally due to the alignment problem. As the database exhibits great changes in pose and expressions and the dictionary does not have sufficient samples, there are many unreliable query descriptors. Because the proposed method considers the query descriptors holistically and joints all of the reliable ones, it achieves a better performance than the others. 4.4.Holistic Face Recognition with OcclusionThis experiment is conducted on the AR database. The AR database contains 120 subjects, including 65 males and 55 females. For each subject, 26 images were taken in two sessions, of which 14 images are nonoccluded and the remainder are occluded by various objects, such as scarves and sunglasses. Experiments are performed on the images of two separate sessions. We selected nonoccluded face images in one session as the samples for each subject. The remaining occluded face images in that session are selected as the queries. Therefore, there are 840 samples and 720 queries in each experimental setting. All images were cropped to . No alignment was performed between the queries and the samples. Some examples of the samples and the queries are shown in Fig. 6. Fig. 6Some examples of the sample and query images. (a) The examples of the sample images. (b) The examples of the query images.  The recognition performance is presented in Table 3. The performance of the proposed method is found to be outstanding. The MKD-SRC and CWS-SRC methods also work well. As is known, most of the SIFT descriptors extracted from the occluded module in a face image are not reliable. Compared to the results of the JDSRC method, we can see that consideration of the reliability of the query descriptors is practical. Thus, the calculation of the weight of the query descriptors is important. Analyzing the misrecognition images by WJSRC, we find that our method works poorly for the face images containing too many descriptors, especially in the case where most of these descriptors are unreliable. Our future work will focus on this issue of face images with too many descriptors. Table 3The recognition performance on the AR database.
5.Conclusion and Future WorkIn this work, a novel framework for robust alignment-free face recognition was proposed. The approach studies the reliability of the query descriptors holistically and utilizes the correlation among them. We demonstrated promising experimental results on images of partial faces, occluded faces, and faces with variations due to different poses and expressions. Comparison of the proposed algorithm with the related algorithms indicated that the proposed method is more robust for alignment-free scenarios. Meanwhile, some methods may be used to improve the robustness, such as optimizing the approach of weight calculation, which will be studied in the future. AcknowledgmentsThis work was supported by the Fundamental Research Funds for the Central Universities (2014KJJCA15), the State Key Laboratory of Acoustics, Chinese Academy of Sciences (SKLA201304), the National Natural Science Foundation of China (61431004), and the Fundamental Research Funds for the Central Universities (2013NT55). We thank Prof. Xiaoming Zhu for helping us revise the organizational structure and grammar issues of the paper. ReferencesX. D. Jiang,
“Asymmetric principal component and discriminant analyses for pattern classification,”
IEEE Trans. Patt. Anal. Mach. Intell., 31
(5), 931
–937
(2009). http://dx.doi.org/10.1109/TPAMI.2008.258 ITPIDJ 0162-8828 Google Scholar
P. Comon,
“Independent component analysis, a new concept?,”
Signal Process., 36 287
–314
(1994). http://dx.doi.org/10.1016/0165-1684(94)90029-9 SPRODR 0165-1684 Google Scholar
B. HeiseleP. HoT. Poggio,
“Face recognition with support vector machines: Global versus component-based approach,”
in Eighth IEEE International Conference on Computer Vision, 2001. ICCV 2001. Proceedings,
688
–694
(2001). http://dx.doi.org/10.1109/ICCV.2001.937693 Google Scholar
I. NaseemR. TogneriM. Bennamoun,
“Linear regression for face recognition,”
IEEE Trans. Pattern Anal. Mach. Intell., 32
(11), 2106
–2112
(2010). http://dx.doi.org/10.1109/TPAMI.2010.128 ITPIDJ 0162-8828 Google Scholar
J. Wrightet al.,
“Robust face recognition via sparse representation,”
IEEE Trans. Pattern Anal. Mach. Intell., 31
(2), 210
–227
(2009). http://dx.doi.org/10.1109/TPAMI.2008.79 ITPIDJ 0162-8828 Google Scholar
R. Heet al.,
“Two-stage nonnegative sparse representation for large-scale face recognition,”
IEEE Trans. Neural Netw. Learn. Syst., 24
(1), 35
–46
(2013). http://dx.doi.org/10.1109/TNNLS.2012.2226471 1045-9227 Google Scholar
J. HuangX. HuangD. Metaxas,
“Simultaneous image transformation and sparse representation recovery,”
in IEEE Conference on Computer Vision and Pattern Recognition. CVPR 2008,
1
–8
(2008). http://dx.doi.org/10.1109/CVPR.2008.4587640 Google Scholar
R. KhorsandiM. Abdel-Mottaleb,
“Gender classification using 2-D ear images and sparse representation,”
in 2013 IEEE Workshop on Applications of Computer Vision (WACV),
461
–466
(2013). http://dx.doi.org/10.1109/WACV.2013.6475055 Google Scholar
I. RamirezP. SprechmannG. Sapiro,
“Classification and clustering via dictionary learning with structured incoherence and shared features,”
in 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR),
3501
–3508
(2010). http://dx.doi.org/10.1109/CVPR.2010.5539964 Google Scholar
J. YangK. YuT. Huang,
“Supervised translation-invariant sparse coding,”
in 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR),
3517
–3524
(2010). http://dx.doi.org/10.1109/CVPR.2010.5539958 Google Scholar
H. Caoet al.,
“Classification of multicolor fluorescence in situ hybridization (M-FISH) images with sparse representation,”
IEEE Trans. Nanobiosci., 11
(2), 111
–118
(2012). http://dx.doi.org/10.1109/TNB.2012.2189414 ITMCEL 1536-1241 Google Scholar
Y. LiA. Ngom,
“Fast sparse representation approaches for the classification of high-dimensional biological data,”
in IEEE Int. Conf. Bioinformatics and Biomedicine,
1
–6
(2012). http://dx.doi.org/10.1109/BIBM.2012.6392688 Google Scholar
A. JulazadehJ. AlirezaieP. Babyn,
“A novel automated approach for segmenting lateral ventricle in MR images of the brain using sparse representation classification and dictionary learning,”
in 11th Int. Conf. Information Science, Signal Processing and their Applications,
888
–893
(2012). http://dx.doi.org/10.1109/ISSPA.2012.6310680 Google Scholar
M. Xuet al.,
“Tumor classification via sparse representation based on metasample,”
in 2th Int. Symposium on Knowledge Acquisition and Modeling,
31
–34
(2009). http://dx.doi.org/10.1109/KAM.2009.310 Google Scholar
J. LaiX. Jiang,
“Modular weighted global sparse representation for robust face recognition,”
IEEE Signal Process. Lett., 19
(9), 571
–574
(2012). http://dx.doi.org/10.1109/LSP.2012.2207112 IESPEJ 1070-9908 Google Scholar
K. Estabridis,
“Automatic target recognition via sparse representation,”
Proc. SPIE, 7696 76960O
(2010). http://dx.doi.org/10.1117/12.849591 PSISDG 0277-786X Google Scholar
Y. ChenT. DoT. Tran,
“Robust face recognition using locally adaptive sparse representation,”
in 17th IEEE Int. Conf. Image Processing (ICIP),
1657
–1660
(2010). http://dx.doi.org/10.1109/ICIP.2010.5652203 Google Scholar
J. Wagneret al.,
“Toward a practical face recognition system: Robust registration and illumination by sparse representation,”
in Conference on IEEE Computer Vision and Pattern Recognition, 2009. CVPR 2009,
597
–604
(2009). http://dx.doi.org/10.1109/CVPR.2009.5206654 Google Scholar
C.-Y. Luet al.,
“Face recognition via weighted sparse representation,”
J. Vis. Commun. Image R, 24 111
–116
(2013). http://dx.doi.org/10.1016/j.jvcir.2012.05.003 JVCRE7 1047-3203 Google Scholar
M. Coxet al.,
“Least squares congealing for unsupervised alignment of images,”
in IEEE Conference on Computer Vision and Pattern Recognition, 2008. CVPR 2008,
1
–8
(2008). http://dx.doi.org/10.1109/CVPR.2008.4587573 Google Scholar
E. Learned-Miller,
“Data driven image models through continuous joint alignment,”
Pattern Anal. Mach. Intell., 28
(2), 236
–250
(2006). http://dx.doi.org/10.1109/TPAMI.2006.34 ITPIDJ 0162-8828 Google Scholar
G. Lowe,
“Distinctive image features from scale-invariant keypoints,”
Int. J. Comput. Vision, 60 91
–110
(2004). http://dx.doi.org/10.1023/B:VISI.0000029664.99615.94 IJCVEQ 0920-5691 Google Scholar
S. LiaoA. K. Jain,
“Partial face recognition: an alignment free approach,”
in 2011 International Joint Conference on Biometrics (IJCB),
1
–8
(2011). http://dx.doi.org/10.1109/IJCB.2011.6117573 Google Scholar
B. SunF. XuJ. He,
“Clustering-weighted SIFT-based classification method via sparse representation,”
J. Electron. Imaging, 23
(4), 043007
(2014). http://dx.doi.org/10.1117/1.JEI.23.4.043007 JEIME5 1017-9909 Google Scholar
H. Bayet al.,
“SURF: speeded up robust features,”
in 9th European Conference on Computer Vision,
404
–417
(2006). http://dx.doi.org/10.1007/11744023_32 Google Scholar
P. N. BelhumeurJ. P. HespanhaD. J. Kriegman,
“Eigenfaces vs. Fisherfaces: recognition using class specific linear projection,”
IEEE Trans. Pattern Anal. Mach. Intell., 19
(7), 711
–720
(1997). http://dx.doi.org/10.1109/34.598228 ITPIDJ 0162-8828 Google Scholar
F. S. SamariaA. C. Harter,
“Parameterisation of a stochastic model for human face identification,”
in Proceedings of the Second IEEE Workshop on Applications of Computer Vision, 1994,
138
–142
(1994). http://dx.doi.org/10.1109/ACV.1994.341300 Google Scholar
A. MartinezR. Benavente,
“The AR face database, Technical report,”
(1998). Google Scholar
X.-T. YuanX. LiuS. Yan,
“Visual classification with multitask joint sparse representation,”
IEEE Trans. Image Process., 21
(10), 4349
–4360
(2012). http://dx.doi.org/10.1109/TIP.2012.2205006 IIPRE4 1057-7149 Google Scholar
H. Namet al.,
“Robust multi-sensor classification via joint sparse representation,”
in 2011 Proceedings of the 14th International Conference on Information Fusion (FUSION),
1
–8
(2011). Google Scholar
S. Shekharet al.,
“Joint sparse representation for robust multimodal biometrics recognition,”
IEEE Trans. Pattern Anal. Mach Intell., 36
(1), 113
–126
(2014). http://dx.doi.org/10.1109/TPAMI.2013.109 ITPIDJ 0162-8828 Google Scholar
H. Zhanget al.,
“Multi-observation visual recognition via joint dynamic sparse representation,”
in 2011 IEEE International Conference on Computer Vision (ICCV),
595
–602
(2011). http://dx.doi.org/10.1109/ICCV.2011.6126293 Google Scholar
H. Zhanget al.,
“Multi-view face recognition via joint dynamic sparse representation,”
in 2011 18th IEEE International Conference on Image Processing (ICIP),
3025
–3028
(2011). http://dx.doi.org/10.1109/ICIP.2011.6116301 Google Scholar
H. Zhanget al.,
“Multi-view automatic target recognition using joint sparse representation,”
IEEE Trans. Aerosp. Electron. Syst., 48
(3), 2481
–2497
(2012). http://dx.doi.org/10.1109/TAES.2012.6237604 IEARAX 0018-9251 Google Scholar
Y. C. PatiR. RezaiifarP. S. Krishnaprasad,
“Orthogonal matching pursuits: Recursive function approximation with applications to wavelet decomposition,”
in 1993 Conference Record of the Twenty-Seventh Asilomar Conference on Signals, Systems and Computers,
40
–44
(1993). http://dx.doi.org/10.1109/ACSSC.1993.342465 Google Scholar
BiographyBo Sun received a BSc in computer science from Beihang University, China, and MSc and PhD degrees from Beijing Normal University, China. He is currently a professor in the Department of Computer Science and Technology at Beijing Normal University. His research interests include pattern recognition, natural language processing, and information systems. He is a member of ACM and a senior member of the China Society of Image and Graphics. Feng Xu received a BSc in electronic science and technology from Beijing Normal University in 2009. He is currently working toward the MSc degree in computer application technology at Beijing Normal University. His research interests include pattern recognition and signal processing. Guoyan Zhou received a BSc in computer science and technology from Beijing Normal University, 2009. She is currently working toward the MSc degree in Computer Application Technology at Beijing Normal University. Her research interest includes signal processing. Jun He received a BSc in optical engineering and a PhD in physical electronics from Beijing Institute of Technology, China, in 1998 and 2003, respectively. Since 2003, she has been with the College of Information Science and Technology of Beijing Normal University, China. She was elected as a lecturer and an assistant professor in 2003 and 2010, respectively. Her research interests include image processing application and pattern recognition. Fengxiang Ge received the PhD degree in communication and information systems from Tsinghua University in 2003. From 2003 to 2005, he was a postdoctoral research associate at the University of Hong Kong. In 2005, he joined Intel Corporation as a senior researcher and an architect. In November 2011, he joined the College of Information Science and Technology, Beijing Normal University, China. His research interests include signal processing and its applications. |




