|
|
1.IntroductionImage superresolution (SR) aims to generate a high-resolution (HR) image from a single image or a set of low-resolution (LR) images. With the fast emergence of high-definition displays at consumer electronics market, such as Nexus 7 () and iPad3 (), there is a great demand to super-resolve existing LR images, so that they can be enjoyably viewed on such readily available HR devices without any visual artifacts. Therefore, the SR problem has gained popularity in image processing community in recent years. Ever since the pioneer work proposed by Huang and Tsai in 1984,1 many improvements have been made in this particular research field. Generally, SR methods that are implemented in spatial domain can be roughly categorized into three classes: the interpolation-based methods,2–8 the reconstruction-based methods,9–11 and the learning-based methods,12–27,28,29,30 each of which has its own distinctive advantages, prior assumptions, and requirements for additional information. For a comprehensive literature survey, the interested reader is referred to Refs. 31 and 32. The simplest interpolation-based SR methods, such as bicubic and Lanczos, use linear interpolation kernels to predict unknown pixels in a higher grid. Because these linear kernels are usually derived under the assumption that natural images are either spatially smooth or band-limited, the interpolation-based SR methods tend to produce smooth HR images with several visual artifacts, such as ringing, aliasing, blocking, and blurry.2,4 In recent years, some sophisticated methods,2–8 in which the kernel coefficients are locally adaptive, have been proposed to reduce these unwanted artifacts. For instance, the regression model used in Refs. 56.–7 and the adaptive normalized convolution technique used in Ref. 8 are very helpful to approximate local structures and obtain somewhat sharp edges. The reconstruction-based SR methods regard the SR problem as an inverse imaging procedure. Moreover, considering that far more pixels than the number given need to be determined, this inverse problem is intrinsically ill-posed. To cope with this, certain priors are incorporated. For example, the gradient profile prior10 and the soft edge smooth prior11 are commonly used for yielding sharp edges. Besides the prior knowledge, the embedded back-projection policy guarantees the consistency between the resultant HR and the LR input images. In general, methods in this category perform better than the interpolation-based methods, but it is still difficult to recover high-frequency (HF) details. Besides, Lin and Shum33 have validated that only under a magnification, can such reconstruction-based methods effectively generate fine details, which, of course, greatly limits their applications. To exceed the limits of the reconstruction-based SR approaches, the learning-based SR methods aim at estimating the HF details that are not explicitly found in the LR input images. In the pioneer work proposed by Freeman et al.,13 these lost HF details are learned from a set of universal LR-HR patch pairs. Several extensions14–21 have been proposed thus far to better predict the correspondences between LR-HR patches from varieties of training images. Although their successful SR capabilities have been substantiated by extensive experimental results, several researchers10,22–24 have pointed out that false HF details are very likely to be introduced if the LR input image is incompatible with the training images. Therefore, many self-learning algorithms22–27,29 have been proposed recently to use the LR input image itself as the only source of LR-HR example patches. Such approaches are all based on the observation that the small patches tend to redundantly repeat themselves many times within the original image scale34 as well as across different image scales.22–24,27,35 Compared to SR approaches using an external database, these self-learning approaches are able to exploit more relevant examples.22,24 In this paper, we propose a self-learning SR method by taking advantage of local structural information and nonlocal patch redundancy (self-similarity) property22–24,27,35 in natural images. First, a set of self LR-HR patch pairs is formed by splitting the LR input image and its smoothened version into overlapped patches. Based on these example patch pairs, a regression model is established to derive the mapping functions that characterize relationships between the LR-HR patches. By exploiting the multiscale patch redundancy in LR image, we successfully obtain the high-order derivation estimation as well as the approximation error of each LR-HR mapping function. Moreover, since cross-scale self-similarity holds better for small scaling factors,23 we adopt a gradual up-sampling scheme, and accumulate the previous reconstructed HR images and their corresponding LR versions for succeeding estimation. Contributions of this paper are twofold:
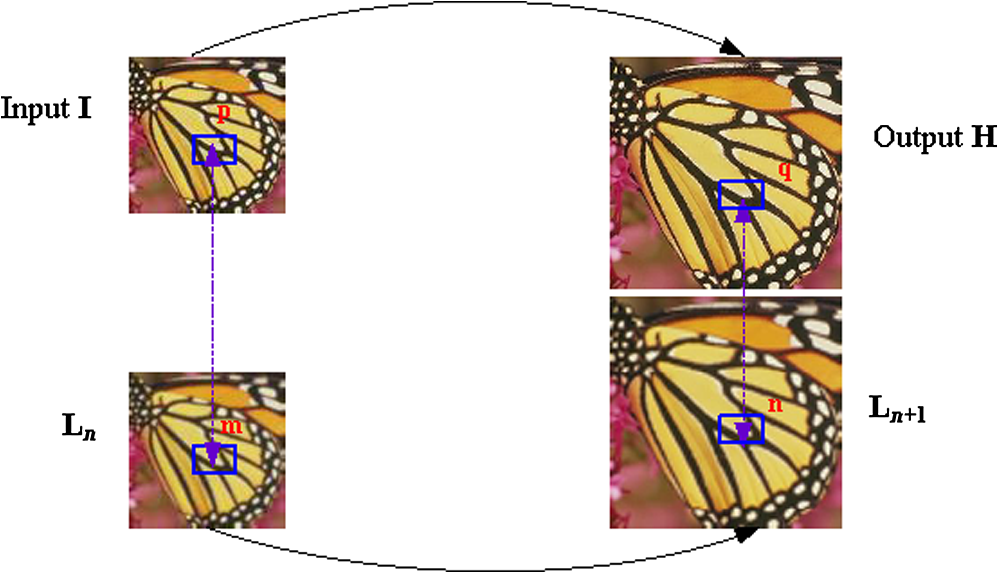
The remainder of this paper is organized as follows. The next section gives a brief overview of related work on local regression model and nonlocal similarity in self-learning SR approaches, respectively. Section 3 details the proposed algorithm. Experimental results and comparisons are demonstrated in Sec. 4. Finally, Sec. 5 concludes this paper. 2.Related Work2.1.Local Regression ModelThe local regression model relates two dependent measurements, and , via an unspecified regression function in which is the estimation error and ideally under the smoothness assumption. One typical application for this model is to predict the function value at any point from the sample pairs . Without any specific assumptions on the samples or regularization terms, this prediction model is usually solved by an -term Taylor series, which approximates the observation as follows: where and denote the first and th derivatives of the regression function. Because Eq. (2) is derived from a local signal representation of the regression model, it is reasonable to estimate the unknown coefficients by using the samples in the vicinity. With respect to this notion, Eq. (2) is reformulated as a weighted least-squares optimization problem where is the number of samples that are near , and represents the similarity between and . If we denote , , , and Eq. (3) is then expressed in the following matrix form: The function defines a diagonal operator that for a vector . The solution of Eq. (4) is easily given by the weighted least-squares estimationThe approaches in Refs. 56.–7 and 28 have validated the effectiveness of the local regression model for recovering complex structures in the SR problem by achieving higher-order derivative approximations (),5 i.e., the first-order derivatives correspond to edge orientations and the second-order derivatives are related to curvatures. 2.2.Nonlocal Similarity in Self-Learning Superresolution ApproachesAs illustrated before, the self-learning SR approaches have been developed to circumvent the false HF details from irrelevant training image by exploiting the multiscale self-similarities in natural images.22–24,27,35 In particular, Glasner et al.22 have unified the reconstruction-based SR and the self-learning SR in the same framework, where the same-scale patch recurrence forms the constraints used in reconstruction-based SR and the across-scale patch recurrence generates exemplar LR-HR patch pairs used in the learning-based SR. By confirming that the local self-similarity assumption holds better for small zooming factors, Freedman and Fattal23 have performed multiple magnification steps of small zooming factors to achieve the desired magnification size, wherein the example patch pairs were extracted from the LR input image and its smoothed version. Both Glasner’s and Freedman’s works have confirmed the effectiveness of the internal patch recurrence in self-learning SR approaches. Further, Zontak and Irani24 have shown that the image statistic that is derived from the internal patch recurrence is more predictive and powerful than the statistic derived from the external images. Accordingly, this powerful internal statistic is adopted by several self-learning SR approaches25–27 as an effective regularization term. For example, by introducing the nonlocal similarity constraint, the nonlocal autoregression model (NARM)25 has ensured the incoherence and sparsity of representation dictionary and consequently made the sparse representation model more suitable for the SR problem. Moreover, under the maximum a posteriori probability framework, Zhang et al.26 have successfully assembled both the nonlocal prior that is obtained from the self-similarity in the same scale and the local prior that is derived from a specific regression model6 to regularize the ill-posed SR problem. Later on, they have extended to multiscale self-similarity for a better image detail synthesis.27 3.Proposed ApproachThe proposed approach is based on a local regression model and the multiscale nonlocal self-similarity, which will be described respectively in Secs. 3.1 and 3.2. Further, an adaptive patch processing strategy is provided in Sec. 3.3 to reduce the time consumption. In the following, we use matrices and to represent the LR input and the HR output images; is the smoothed version of , and is an enlarged version of . The bolded lowercase and represent the column vectors of two image patches that are extracted from and , respectively; and denote the column vectors of two image patches that are extracted from and , respectively. Without specific notification, we assume that , , , and are related. That is, is the most similar patch to among all other patches in image ; patches and have the same coordinate for the center pixel, as presented by the dashed lines in Fig. 1. Given that image has more HF details than , constitutes the self-exemplar LR-HR patch pairs in the proposed method. In addition, because lacks the HF details in , is another group of LR-HR patch pairs. 3.1.Local Patch Representation Based on a Local Regression ModelAs mentioned above, the task of learning-based SR approaches is to find the relations between LR-HR patches. In the proposed method, this relation is interpreted as an unspecified mapping function that associates each LR-HR patch pair in the following way . The assumption that and are similar patches can also be interpreted as that is “near” in terms of geometric layout. Therefore, as in Sec. 2.1, this mapping function can also be estimated via Taylor series where denotes the Hadamard product (also known as element-wise product). By neglecting noise and blurry in LR image, we come to (which is a very basic assumption in several self-learning based SR approaches, such as Refs. 23 and 28), Eq. (6) is therefore reformulated as where represents the residual error. Although and are both taken from smooth images, it is agreed that comparably contains more HF details than does,23 and therefore leaves only the HF information.13,23,28 In view of this, Eq. (7), in fact, generates HR patches by imposing HF details to the related LR patches, which is actually the basic scheme of learning-based SR approaches.From Eq. (7), we have to infer and first so as to obtain each HR patch . It is worth noting that for many existing SR approaches, only the first-order derivative is inferred. For example, in Refs. 13 and 23, the first-order derivative is assumed to be a constant, whereas in Ref. 28, this first-order derivative is estimated from an external database. However, it is generally agreed that only using the first-order derivative is insufficient to recover complex structures, such as curvatures; moreover, using external images is highly probable to introduce unfaithful image details. In the next subsection, we will present how to extend the first-order derivative estimation to the second order by exploiting the multiscale self-similarity property in a given LR image, and also provide a closed-form solution to this second-order estimation. 3.2.Derivative Estimation Based on Multiscale Local Self-SimilarityAccording to nonlocal patch redundancy, each patch is very likely to have many “neighbors,” which are geometrically similar to it but are spatially far from it. Suppose is a similar patch to in image , as in Eq. (6), can be approximated as follows: The column vector is ’s paired HR patch in image , and the column vector also refers to the approximation error as does in Eq. (7). As in Sec. 2.1, by incorporating the -most similar patches and their paired HR patches , Eq. (8) can be transformed into the following optimization problem: where measures the similarity between patches and . Similar to Eq. (3), the above optimization problem could be easily solved by the weighted least-squares estimation that as shown in Eq. (5). We should remind the reader that unlike Eq. (3), in which all the variables are scalars, the variables inside in Eq. (9) are all in the column vector forms. Thus, we should redefine the specific formation of , , and by taking account of the vector forms and the Hadamard product in Eq. (9). In the proposed method, these three variables are devised as follows: where is an column vector with all elements equal to one, and is of size that cascades each column vector .After plugging the least-squares solution of Eq. (9) back into Eq. (8), the residual error is easily obtained. Further, by simply averaging all the can the approximation error in Eq. (7) be also obtained. In summary, we not only provide a closed-form solution of the derivative estimation, but also approximate the residual error that is caused by omitting higher-order derivative terms. Intuitively, for the derivative estimation to be reliable, the number of independent equations in Eq. (9) must exceed the number of unknown derivative coefficients. With the assumption that and are not constant within the patch (it is a reasonable assumption, for example, in an edge patch, the pixels across this edge are very likely to have larger first-order derivative than pixels along it), the number of unknown derivative coefficients is then related to the patch size and the derivative order. For instance, if a patch contains and a second-order derivative estimation is required, then the derivative coefficients are up to , implying that the demanded number of equations or the number of similar patches should be above . Naturally, one question arises: are we able to find such enough similar patches in a single image? A statistical analysis made in Ref. 22 shows that the smooth patches recur much more frequently than the detailed patches do. However, in our case, we have to find the same patch numbers to ensure a reliable second-order derivative estimation, no matter whether these patches are highly detailed or not. Recently, Zontak and Irani24 have shown that the patches with different gradient magnitudes need to search at different distance to ensure the same number of similar patches, and have also provided an empirical function. According to this function, we surprisingly find that the search region should be even beyond the image size for some highly textured patches so as to get a reliable second-order derivative estimation. This reveals that for highly textured patches, search for their similar patches in the same image scale is very insufficient. To overcome this insufficient patch problem, we extend the same-scale local search to multiple scales. More specifically, based on the gradual magnification scheme, not only the down-scaled images of the current image resolution, but also all the images from the previous estimates, including the initial input image, are employed to find the similar patches. Take a two-iteration estimate for example. In the first iteration, we respectively search the similar patches in and its two down-scaled images to estimate and (these two down-scaled images of are obtained by down sampling with the bicubic interpolation under scale , , 2). After that, the intermediate HR image is generated by merging all the reconstructed HR patches according to Eq. (7), with a fusion of the overlapping regions between the adjacent patches. In the second iteration, we search the similar patches, respectively, in , and the two down-scaled versions of to estimate the second derivatives. Subsequently, we obtain the second intermediate HR image , and generate the HR output image by resizing to the desired size using the bicubic interpolation. We can see that for the derivative estimation in higher resolution levels, the required number of similar patches with respect to each image in the training set is reduced because more images in lower resolutions can be utilized. Although incorporating multiscale images guarantees a reliable derivative estimation, the additional exhaustive search for similar patches in other images would inevitably increase time complexity. Therefore, similar patches in coarser scales and lower resolutions are selected at the “relative” coordinates. For instance, in the second iteration process of the previous example, if the similar patch found in is centered at , then the additional similar patch in the down-scaled image of is centered at (), where denotes the down-scale level, and the similar patch in the lower-resolution image is centered at (), where denotes the gradual up-scaling factor. 3.3.Computational Speed-UpsIn Sec. 3.1, we translate the estimation of the relations between LR-HR patches to the estimation of the regression function derivatives by leveraging a local regression model. In Sec. 3.2, we further adopt the nonlocal similarity across multiple image scales to provide a closed-form solution. In this subsection, an adaptive patch processing strategy is introduced to reduce the time consumption. Intuitively, there is no need to estimate the high-order derivatives for smooth regions since their intensity values are nearly constant. Moreover, since natural images generally contain much more smooth regions than the detailed ones,22,28,36 it is efficient to process different patch types (smoothed or detailed) in different ways. To discriminate the textured areas from the flat areas, an effective pixel classification criterion37 TM is adopted, which provides a quantitative assessment of image geometric structures using the structure tensor and the intensity standard deviation of each patch. More specifically, , in which and are the eigen values of the structure tensor computed from each image patch, and is the second moment of a gray-level cumulative histogram of that patch. By analyzing the cumulative TM histogram, three regions with different texture magnitudes are obtained: where is the TM value of the pixel at location ; and are the bin values that correspond, respectively, to 70% and 30% in the cumulative TM histogram; , , and respectively represent the hard-detailed, medium-detailed, and smooth regions.After the classification, an adaptive derivative order estimation scheme is implemented: for hard-detailed regions, we estimate their second-order derivatives to recover complex structures; for medium-detailed regions, a first-order derivative estimation is sufficient; for smooth regions, we simply paste the results from the previous HR estimation. Experiments show that such an adaptive patch processing strategy greatly reduces the time consumption of second-order scheme, which estimates the second-order derivative for both hard- and medium-textured regions, to 0.625 times without any obvious visual quality compromise. Algorithm 1 describes the entire SR process of the proposed method. Algorithm 1The proposed method.
4.Experimental Results and AnalysisTo evaluate the effectiveness of the proposed method, experiments on 14 standard images (shown in Fig. 2) are conducted. Several state-of-the-art SR approaches, including Glasner’s method,22 Fattal’s method,10 Freedman’s method,23 the GPR method,29 the SC-based method,19 Shan’s method,9 Kim’s method,21 the ANR method,30 and the NARM method,25 are selected as comparison baselines. The results of the first three approaches are straightly downloaded from http://www.cs.huji.ac.il/~raananf/projects/lss_upscale/sup_images/index.html and for the rest six approaches we run the source codes that are available at their authors’ homepage. Fig. 2Test images used in our experiments. (a) Original HR images used in and magnification case. (b) LR images used in magnification case.  Two quantitative measures, peak signal-to-noise ratio (PSNR) and structural similarity (SSIM) index,38 are adopted to evaluate the objective performance. A high PSNR score indicates that the reconstructed HR image contains little distortion, and a SSIM value near 1 implies that the resultant HR image has a very similar structure to the ground truth. It is worth noting that due to the gradual magnification scheme, any minor structure distortions and estimation errors may propagate and accumulate over several iterations.28 Thus, the HR image obtained by the proposed method is inconsistent with the initial LR image. To alleviate inconsistency, a simple back-projection policy19 is adopted to postprocess the reconstructed HR image. Unless otherwise specified, the presented SR results are postprocessed by the back-projection. 4.1.Experimental ConfigurationIn the following experiments, we straightly use the images shown in Fig. 2(b) as the LR input images, while the other LR input images are generated by down sampling (using the bicubic interpolator) the images shown in Fig. 2(a). In the proposed method, the patch size is and four pixels are overlapped between the adjacent patches. To reduce the computational complexity, similar patches are found within the searching region. The parameter in Eq. (9), which is used to compute the similarity, is fixed to 10.14. The gradual upscaling factor is set to 1.5. The smooth image is generated by convolving with a Gaussian filter with a standard deviation of 0.65. The upscaled image is obtained by bicubic interpolation. 4.2.Experimental ResultsFor color images, we only super resolve their luminance channel since human eyes are more sensitive to illuminant changes. Accordingly, we compare the quantitative difference only on the luminance channel between the ground truth and the HR output image. Table 1 summarizes the quantitative comparisons on images shown in Fig. 2(a). Among those listed approaches, ANR,30 Kim’s method,21 and SC-based19 are all training-based SR approaches, whereas GPR,29 Shan’s method,9 NRAM,25 and the proposed approach are training-free. It is worth noting that Kim’s method not only uses external dataset as ANR30 and SC-based19 do, but also postprocesses the resultant image by imposing an image edge prior. As in Table 1, Kim’s method on average gives the best PSNR and SSIM scores. However, even for the image Butterfly, where Kim’s method presents nearly the highest gain in both PSNR and SSIM over the proposed method, we observe no apparent visual difference between these two methods (see Fig. 3 for details), despite that there are some jaggies in our method. Nevertheless, such jaggy effects are in fact introduced by the back-projection process, as illustrated in Figs. 3(b) and 3(c). Since jaggies are highly probable to cause the degradation of the objective performance of the proposed method, we believe that using certain de-jagged techniques could further improve our method, a most recent one of which can be found in Ref. 39. Table 1Comparisons on peak signal-to-noise ratio (PSNR) values (dB) and structural similarity (SSIM) values (PSNR/SSIM) for 2× magnification.
Fig. 3Quantitative and qualitative SR comparisons () on image Butterfly. (a) LR image. (b) Our result before back-projection (PSNR: 25.902 dB, SSIM: 0.926). (c) Our result after back-projection. (PSNR: 29.943 dB, SSIM: 0.956). (d) Kim’s method21 (PSNR: 30.448 dB, SSIM: 0.959). Note that the artifacts in (c) are, in fact, introduced by back-projection.  In general, among all the training-free SR approaches, our method gives the best performance in terms of PSNR and SSIM. As for the other training-based SR approaches, we have to point out that they use thousands of training images to assure that enough relevant information can be utilized in the SR reconstruction. However, by using a single image only, the proposed method is able to reach a comparable objective performance, which validates that the relevant example LR-HR patch pairs can be found by fully exploiting the multiscale patch similarity. For visual comparison, we carry out magnification on LR images obtained from Fig. 2(a) and magnification on images in Fig. 2(b). Since the pretrained dictionaries in the SC-based19 approach are only for a zoom factor of 2, this approach is excluded in the following visual comparisons. In the first magnification case, the proposed method is compared with the GPR method,29 Shan’s method,9 Kim’s method,21 the ANR method,30 and the NARM method.25 Figure 4 shows the experimental results on images Barbara, Girl, Fence, and Hat, in which the local regions of interest (ROIs) in blue boxes are presented at the lower corner for providing a better comparison. Based on a universal dictionary, which is pretrained from thousands of images, the ANR method30 appears to generate natural-looking results. Nevertheless, it is clumsy in preserving sharp edges, e.g., the blurry eyelashes in image Girl, due to the fact that a universal dictionary fails to accurately represent the complex details. Leveraged with a generic image prior model, Kim’s method can effectively preserve some tiny details (see the ROI in image Girl), but it is prone to create ringing artifacts along some complicated edges, e.g., the characters in the image Hat. As for the NARM25 and Shan’s methods,9 they are both somewhat prone to smooth HF details. The GPR method29 seems to have difficulty in synthesizing faithful details, i.e., the characters in image Hat are badly recovered. By contrast, the proposed algorithm is able to provide sharper edges and more photorealistic details than other methods. For example, in images Barbara and Fence, the details shown in our ROIs are more distinctive in comparison with other methods; in images Girl and Hat, very fine details, such as eyelashes and the contour of characters, are well preserved. Fig. 4Superresolution () comparison on four images: Barbara, Girl, Fence, and Hat. (a) The ground truth; (b)–(g) the reconstructed HR results by ANR,30 Kim’s method,21 the proposed approach, NARM,25 GPR,29 and Shan’s method,9 respectively.  In addition, the objective comparisons of the HR results under magnification are listed in Table 2, where our result appears not as superior as in the case of magnification. However, we also find that our method, in fact, provides the best appealing visual details, i.e., the ROIs in Fig. 4(d) are consistently more vivid than those in Fig. 4(b), although the latter gives the almost highest PSNR and SSIM values; Hat image is poorly reconstructed by GPR but it has higher PSNR value than ours. This paradox suggests that the objective quality degradation of our method can be only attributed to the inconsistency caused by the gradual magnification scheme. Although this inconsistence can be alleviated by the back-projection policy, Freedman and Fattal23 have further claimed that such inconsistency should be alleviated at an early stage. Their claim also explains why our method gives superior quantitative performance in magnification case but fails to do so in magnification case, since in magnification, only two iterations are required in the proposed method. Table 2Comparisons on peak signal-to-noise ratio (PSNR) values (dB) and structural similarity (SSIM) values (PSNR/SSIM) for 3× magnification.
To further inspect the effectiveness of our method, we continue to compare with more algorithms in Figs. 5Fig. 6–7 under a magnification. Since the code of the NARM25 method is only devised for zoom factors of 2 and 3, we also exclude this method in the subsequent visual comparisons. Among all the reconstructed HR images shown in Figs. 5–7, Freedman’s method23 tends to blur HF details since it simply assumes that the first-order derivative of the mapping function is a constant value. Although Fattal’s method10 applies imposed edge statistics to generate sharp edges, it produces staircase artifacts along edges as shown in Fig. 6(g). Glasner’s method22 avoids these unwanted staircase artifacts and provides somewhat pleasant results. Nevertheless, this particular method fails to reproduce plausible details, such as the character “9” in Fig. 7(f). On the contrary, as reflected in all the ROIs, the proposed method outperforms the others by providing more reasonable details. Although there are some jaggies in our results, such as Fig. 7(e), we should point out that they are mainly introduced by the simple back-projection process. As reflected in Fig. 8(b), prior to the back-projection, our result presents more distinguishable details. Although Fig. 8(b) presents a kind of overestimation, we in fact cause this artifact on purpose since the subsequent back-projection step weakens the details. Moreover, quantitative comparisons are also made. Since no ground truth is available in magnification, we adopt a no-reference image assessment natural image quality evaluator (NIQE)40 to indicate the quality of reconstructed HR image. NIQE reflects how the perceived image deviates from the statistical regularities calculated from natural images, a small value of which suggests a better image quality. From all the results in Figs. 5–7, we see that our method provides the lowest NIQE values. Fig. 5Superresolution () comparison on image Sculpture. (a)–(h) are the reconstructed HR results by ANR,30 GPR,29 Kim’s method,21 Shan’s method,9 the proposed approach, Glasner’s method,22 Fattal’s method,10 and Freedman’s method,23 respectively. The numbers in bracket denote NIQE40 values.  Fig. 6Superresolution () comparison on image Kid. (a)–(h) are the reconstructed HR results by ANR,30 GPR,29 Kim’s method,21 Shan’s method,9 the proposed approach, Glasner’s method,22 Fattal’s method,10 and Freedman’s method,23 respectively. The numbers in brackets denote NIQE40 values.  Fig. 7Superresolution () comparison on image Chip. (a)–(h) are the reconstructed HR results by ANR,30 GPR,29 Kim’s method,21 Shan’s method,9 the proposed approach, Glasner’s method,22 Fattal’s method,10 and Freedman’s method,23 respectively. The numbers in brackets denote NIQE40 values.  To sum up, the advantages of the proposed method are attributed to the combination of the local regression model and the multiscale patch redundancy property: (1) we estimate the higher-order derivative of the mapping function, so that complex details such as curvature can be well preserved and enhanced; (2) exploiting the self multiscale redundancy helps to find more related patches than using an external database, without introducing false details. 4.3.Discussion on Down-Sampling MethodAs illustrated in Ref. 7, the down-sampling method also affects the SR algorithms, because in the synthesis experiments, the LR input images are usually obtained by down sampling the original image. Therefore, if a proper down-sampling method is applied, the LR image will have fewer artifacts, which lead to a better reconstructed HR image. In Table 3, the influences of four down-sampling methods on the proposed method, namely, “Nearest,” “Bilinear,” “Bicubic,” and “Lanczos,” are quantified in terms of PSNR and SSIM, using the test images in Fig. 2(a) under a magnification. Note that we do not postprocess the SR results (back-projection) in this case, since we want to examine how the down-sampling method influences our algorithm. Surprisingly, the listed numerical results seem to be a violation of the claim in Ref. 7, since the simple bilinear method outperforms others. However, we notice that the SR results on images down sampled by bicubic are always sharper than the results by bilinear method, which, we believe, causes the degradation of objective performance of the bicubic method since overestimation may occur in some highly textured regions. However, we also found in our experiments that after the back-projection, the average PSNR gain obtained by bicubic over bilinear is higher than 4 dB. Therefore, in all of our experiments, the bicubic interpolation is used as the down-sampling method. Table 3Comparisons of different down-sampling methods in terms of peak signal-to-noise ratio (PSNR) and structural similarity (SSIM).
4.4.Discussion on the Derivative OrderHere, we conduct an empirical study on the effect of derivative orders on the recovery of complex details. Four different derivative order settings in the nonsmooth patches are adopted for comparison, such as the zero-order estimation, the first-order estimation, the second-order estimation, and the adaptive order estimation used in the proposed method. The zero-order derivative estimation refers to assigning , , and in Eq. (7), and a similar notion goes for the first-order derivative estimation by assigning . As indicated in Fig. 9, higher-order derivative estimation helps to produce fine textural details. For example, the zero-order estimation causes very severe block effects. On the other hand, the other three derivative estimation types successfully restore the complex details. Moreover, achieving second-order derivative estimation even preserves the subtle structure changes in kid’s eyelashes, as shown in Figs. 9(c) and 9(d). Although there are no apparent visual differences between Figs. 9(c) and 9(d), the adaptive estimation strategy runs faster than estimating second-order derivative on all detailed patches. To sum up, the adaptive order strategy not only synthesizes complex details, but is also time efficient. 4.5.Discussion on ParametersFor the proposed method, it is important to choose proper parameters so as to obtain good SR performance. In general, there are six parameters to be determined: the patch size, the overlapping step, the deviation of Gaussian filter, the gradual scaling factor, the size of search region, and the smoothing parameter in Eq. (9) to compute similarity. We found that our algorithm is insensitive to the last three parameters in a reasonable range. In the following, we will elaborate the influences of the first three parameters, respectively. 4.5.1.Influence of patch size and overlapping stepIntuitively, using a large patch size tends to produce a smooth result and using a small patch size may introduce unwanted artifacts in flat areas. In the proposed method, the patch size also determines the number of derivative coefficients that need to be estimated. For example, if the patch size is a little large, say , for a second-order derivative estimation, we have to find at least 162 similar patches in multiscale versions of the input image. Finding such a large number of patches with high similarity is unrealistic. In addition, the ones that are not the first few nearest patches are very likely to be quite different from the target patch. In light of this, patch size cannot be very large in the proposed method. Therefore, we only discuss the effects caused by different patch sizes of , , and , and show their reconstructed results on image Girl and Hat under a magnification in Fig. 10. Fig. 10The SR results (before back-projection) obtained by different patch sizes. (a) The ground truth. (b) Patch size is . (c) Patch size is . (d) Patch size is .  As shown in Fig. 10, the freckles in image Girl are well preserved by using patch size , whereas the other two patch size settings are prone to blurring such details. Nevertheless, some unwanted artifacts are introduced in image Hat by using patch size , such as the black dots along the hat edge, while the results obtained by other patch sizes are more pleasant. Besides, we have found that applying the patch size of in our approach greatly increases the running time, which takes 10 times more than what is taken by running with patches. Therefore, to balance the reconstruction quality and the time efficiency, we suggest using the patch size of in the proposed method. In addition, when patch size is fixed, a larger overlapping step leads to a better SR result. To this end, we use an overlapping step of four in the proposed method, as suggested in the SC-based SR19 method. 4.5.2.Influence of deviation of Gaussian filterIn the proposed method, the Gaussian filter is used to generate the blurred image . A large deviation of the Gaussian filter leads to a blurrier , and consequently presents a more obvious HF enhancement according to Eq. (7). A supported example is shown in Fig. 11, in which a higher Gaussian derivation is prone to overestimation. However, considering that the subsequent back-projection will weaken the image details, we recommend a large Gaussian derivation in the first SR process. 5.ConclusionIn this paper, we present a new learning-based SR method for single image. Without any external training database, the proposed method establishes the relations between self LR-HR patches by leveraging the local regression model and the multiscale nonlocal patch redundancy. To better guarantee the cross-scale similarity, a gradual up-scaling scheme is also adopted, and previous estimates are accumulated for the next derivative estimation. In addition, an adaptive patch-based processing strategy is employed to reduce time consumption. Extensive experimental results, further, show how this proposed method improves over many existing learning-based SR approaches. In general, benefiting from a closed-form solution to high-order derivative estimation, the proposed method yields more photorealistic HR images with sharp details. In the future, we plan to extend the proposed method in the following ways. (1) Adaptive patch size. As illustrated in Sec. 4.5.1, a large patch size is appropriate in smooth regions and a small patch size helps to recover subtle image details. Therefore, applying these two complementary properties in a combined adaptive patch size policy will further improve the proposed method. (2) Suitable patch features. Several works have pointed out that the way to represent the image patches also affects SR algorithms. In the proposed method, the patch itself is directly used as a basic feature. Other feature descriptors can also be employed, such as contrast-normalized patch and the patch derivative. (3) Contaminated image. Currently, the proposed method could only deal with clean images, and directly applying it to contaminated images would either introduce unwanted artifacts, e.g., the noise amplification effect in noisy images, or no significant improvement in blurry images. For noisy images, the assumption in Eq. (6) that is no longer valid; for blurry images, the blur kernel used in generating should be refined.41 One possible alternative is to extend the nonlocal patch redundancy to image denoising and image deblurring, which has been very effective in many image processing works.34,41–43 AcknowledgmentsThe work in this paper was supported by Brother Industries, Ltd., Japan. We would like to thank Mr. Masaki Kondo for the constructive comments and successive encouragement. ReferencesT. S. HuangR. Y. Tsai,
“Multi-frame image restoration and registration,”
Adv. Comput. Vis. Image Process., 1
(2), 317
–339
(1984). Google Scholar
L. ZhangX. Wu,
“An edge-guided image interpolation algorithm via directional filtering and data fusion,”
IEEE Trans. Image Process., 15
(8), 2226
–2238
(2006). http://dx.doi.org/10.1109/TIP.2006.877407 IIPRE4 1057-7149 Google Scholar
X. ZhangX. Wu,
“Image interpolation by adaptive 2-D autoregressive modeling and soft-decision estimation,”
IEEE Trans. Image Process., 17
(6), 887
–896
(2008). http://dx.doi.org/10.1109/TIP.2008.924279 IIPRE4 1057-7149 Google Scholar
X. LiM. T. Orchard,
“New edge-directed interpolation,”
IEEE Trans. Image Process., 10
(10), 1521
–1527
(2001). http://dx.doi.org/10.1109/83.951537 IIPRE4 1057-7149 Google Scholar
F. ZhouW. YangQ. Liao,
“Interpolation-based image super-resolution using multi-surface fitting,”
IEEE Trans. Image Process., 21
(7), 3312
–3318
(2012). http://dx.doi.org/10.1109/TIP.2012.2189576 IIPRE4 1057-7149 Google Scholar
H. TakedaS. FarsiuP. Milanfar,
“Kernel regression for image processing and reconstruction,”
IEEE Trans. Image Process., 16
(2), 349
–366
(2007). http://dx.doi.org/10.1109/TIP.2006.888330 IIPRE4 1057-7149 Google Scholar
T.-M. KuoS.-C. Tai,
“On designing efficient superresolution algorithms by regression models,”
J. Electron. Imaging, 22
(3), 033002
(2013). http://dx.doi.org/10.1117/1.JEI.22.3.033002 JEIME5 1017-9909 Google Scholar
T. Q. PhamL. J. van VlietK. Schutte,
“Robust fusion of irregularly sampled data using adaptive normalized convolution,”
EURASIP J. Appl. Signal Process., 1
–12
(2006). http://dx.doi.org/10.1155/ASP/2006/83268 1110-8657 Google Scholar
Q. Shanet al.,
“Fast image/video upsampling,”
ACM Trans. Graph., 27
(5), 1531
–1537
(2008). http://dx.doi.org/10.1145/1409060 ATGRDF 0730-0301 Google Scholar
R. Fattal,
“Image upsampling via imposed edge statistics,”
ACM Trans. Graph., 26
(3), 95
(2007). http://dx.doi.org/10.1145/1276377 ATGRDF 0730-0301 Google Scholar
S. Daiet al.,
“Soft edge smoothness prior for alpha channel super resolution,”
in Proc. of IEEE Int. Conf. on Computer Vision,
17
–22
(2007). Google Scholar
F. Liuet al.,
“Visual-quality optimizing super resolution,”
Comput. Graph. Forum, 28
(1), 127
–140
(2009). http://dx.doi.org/10.1111/cgf.2009.28.issue-1 CGFODY 0167-7055 Google Scholar
W. T. FreemanT. R. JonesE. C. Pasztor,
“Example-based super-resolution,”
IEEE Comput. Graph. Appl., 22
(2), 56
–65
(2002). http://dx.doi.org/10.1109/38.988747 ICGADZ 0272-1716 Google Scholar
H. ChangD.-Y. YeungY. Xiong,
“Super-resolution through neighbor embedding,”
in Proc. IEEE Comput. Soc. Conf. on Computer Vision and Pattern Recognition,
275
–282
(2004). Google Scholar
J. Yuet al.,
“A unified learning framework for single image super-resolution,”
IEEE Trans. Neural Netw. Learn. Syst., 25
(4), 780
–792
(2014). http://dx.doi.org/10.1109/TNNLS.2013.2281313 2162-237X Google Scholar
J. Yanget al.,
“Coupled dictionary training for image super-resolution,”
IEEE Trans. Image Process., 21
(8), 3467
–3478
(2012). http://dx.doi.org/10.1109/TIP.2012.2192127 IIPRE4 1057-7149 Google Scholar
S. Maet al.,
“Fast image super resolution via local regression,”
in Proc. IEEE International Conference on Pattern Recognition,
3128
–3131
(2012). Google Scholar
W. Donget al.,
“Image deblurring and super-resolution by adaptive sparse domain selection and adaptive regularization,”
IEEE Trans. Image Process., 20
(7), 1838
–1857
(2011). http://dx.doi.org/10.1109/TIP.2011.2108306 IIPRE4 1057-7149 Google Scholar
J. Yanget al.,
“Image super-resolution via sparse representation,”
IEEE Trans. Image Process., 19
(11), 2861
–2873
(2010). http://dx.doi.org/10.1109/TIP.2010.2050625 IIPRE4 1057-7149 Google Scholar
X. Gaoet al.,
“Joint learning for single-image super-resolution via a coupled constraint,”
IEEE Trans. Image Process., 21
(2), 469
–480
(2012). http://dx.doi.org/10.1109/TIP.2011.2161482 IIPRE4 1057-7149 Google Scholar
K. KimY. Kwon,
“Single-image super-resolution using sparse regression and natural image prior,”
IEEE Trans. Pattern Anal. Mach. Intell., 32
(6), 1127
–1133
(2010). http://dx.doi.org/10.1109/TPAMI.2010.25 ITPIDJ 0162-8828 Google Scholar
D. GlasnerS. BagonM. Irani,
“Super-resolution from a single image,”
in Proc. of IEEE Int. Con. on Computer Vision,
(2009). Google Scholar
G. FreedmanR. Fattal,
“Image and video upscaling from local self-examples,”
ACM Trans. Graph., 30
(2), 1
–10
(2011). http://dx.doi.org/10.1145/1944846 ATGRDF 0730-0301 Google Scholar
M. ZontakM. Irani,
“Internal statistics of a single natural image,”
in Proc. IEEE Comput. Soc. Conf. on Computer Vision and Pattern Recognition,
977
–984
(2011). Google Scholar
W. Donget al.,
“Sparse representation based image interpolation with nonlocal autoregressive modeling,”
IEEE Trans. Image Process., 22
(4), 1382
–1394
(2013). http://dx.doi.org/10.1109/TIP.2012.2231086 IIPRE4 1057-7149 Google Scholar
K. Zhanget al.,
“Single image super-resolution with non-local means and steering kernel regression,”
IEEE Trans. Image Process., 21
(11), 4544
–4555
(2012). http://dx.doi.org/10.1109/TIP.2012.2208977 IIPRE4 1057-7149 Google Scholar
K. Zhanget al.,
“Single image super-resolution with multiscale similarity learning,”
IEEE Trans. Image Process., 24
(10), 1648
–1659
(2013). http://dx.doi.org/10.1109/TNNLS.2013.2262001 IIPRE4 1057-7149 Google Scholar
J. YangZ. LinS. Cohen,
“Fast image super-resolution based on in-place example regression,”
in Proc. IEEE Comput. Soc. Conf. on Computer Vision and Pattern Recognition,
1059
–1066
(2013). Google Scholar
H. HeW.-C. Siu,
“Single image super-resolution using Gaussian process regression,”
in Proc. IEEE Comput. Soc. Conf. on Computer Vision and Pattern Recognition,
449
–456
(2011). Google Scholar
R. TimofteV. D. SmetL. V. Gool,
“Anchored neighborhood regression for fast example-based super-resolution,”
in Proc. of IEEE Int. Con. on Computer Vision,
(2013). Google Scholar
S. C. ParkM. K. ParkM. G. Kang,
“Super-resolution image reconstruction: a technique overview,”
IEEE Signal Process. Mag., 20 21
–36
(2003). http://dx.doi.org/10.1109/MSP.2003.1203207 ISPRE6 1053-5888 Google Scholar
P. Milanfar, Super Resolution Imaging, CRC Press, Florida
(2011). Google Scholar
Z. LinH. Shum,
“Fundamental limits of reconstruction-based superresolution algorithms under local translation,”
IEEE Trans. Pattern Anal. Mach. Intell., 26
(1), 83
–97
(2004). http://dx.doi.org/10.1109/TPAMI.2004.1261081 ITPIDJ 0162-8828 Google Scholar
A. BuadesB. CollJ. M. Morel,
“A non-local algorithm for image denoising,”
in Proc. IEEE Comput. Soc. Conf. on Computer Vision and Pattern Recognition,
60
–65
(2005). Google Scholar
M. ZontakI. MosseriM. Irani,
“Separating signal from noise using patch recurrence across scales,”
in Proc. IEEE Comput. Soc. Conf. on Computer Vision and Pattern Recognition,
1195
–1202
(2013). Google Scholar
Q. ShanJ. JiaA. Agarwala,
“High-quality motion deblurring from a single image,”
ACM Trans. Graph., 27
(5), 73
(2008). http://dx.doi.org/10.1145/1409060 ATGRDF 0730-0301 Google Scholar
J. HuY. Luo,
“Non-local means algorithm with adaptive patch size and bandwidth,”
Optik, 124
(22), 5639
–5645
(2013). http://dx.doi.org/10.1016/j.ijleo.2013.04.009 OTIKAJ 0030-4026 Google Scholar
Z. Wanget al.,
“Image quality assessment: from error visibility to structural similarity,”
IEEE Trans. Image Process., 13
(4), 600
–612
(2004). http://dx.doi.org/10.1109/TIP.2003.819861 IIPRE4 1057-7149 Google Scholar
S.-C. TaiT.-M. KuoH.-J. Chen,
“Artifact-free superresolution algorithm with natural texture preservation,”
J. Electron. Imaging, 23
(1), 013020
(2014). http://dx.doi.org/10.1117/1.JEI.23.1.013020 JEIME5 1017-9909 Google Scholar
A. MittalR. SoundararajanA. C. Bovik,
“Making a ‘completely blind’ image quality analyzer,”
IEEE Signal Process. Lett., 20
(3), 209
–212
(2013). http://dx.doi.org/10.1109/LSP.2012.2227726 IESPEJ 1070-9908 Google Scholar
T. MichaeliM. Irani,
“Nonparametric blind super-resolution,”
in Proc. of IEEE Int. Con. on Computer Vision,
945
–952
(2013). Google Scholar
D. Van De VilleM. Kocher,
“Nonlocal means with dimensionality reduction and SURE-based parameter selection,”
IEEE Trans. Image Process., 20
(9), 2683
–2690
(2011). http://dx.doi.org/10.1109/TIP.2011.2121083 IIPRE4 1057-7149 Google Scholar
C. A. DeledalleJ. Salmon,
“Non-local methods with shape adaptive patches (NLM-SAP),”
J. Math. Imaging Vis., 43
(2), 103
–120
(2012). http://dx.doi.org/10.1007/s10851-011-0294-y JIMVEC 0924-9907 Google Scholar
BiographyJing Hu received her BE degree from the School of Automation at the University of Electronic Science and Technology of China, Sichuan, in 2009. She is working toward the PhD degree in the Department of Automation at Tsinghua University. Her current research interests include superresolution and image denoising. Yupin Luo is a professor in the Department of Automation at Tsinghua University. He received his BS degree from Hunan University in 1982, and his EM and PhD degrees from Nagoya Institute of Technology, Japan, in 1987 and 1990, respectively. His current research interest is in the area of image processing, graph theory, and artificial intelligence. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||