|
|
1.IntroductionThe color rendering accuracy of a digital imaging acquisition device is a key factor to the overall perceived image quality.1–3 There are mainly two modules responsible for the color rendering accuracy in a digital camera: the former is the illuminant estimation and correction module, the latter is the color matrix transformation. These two modules together form what may be called the color correction pipeline. The first stage of the color correction pipeline1,3 aims to render the acquired image as closely as possible to what a human observer would have perceived if placed in the original scene, emulating the color constancy feature of the human visual system (HVS), i.e., the ability of perceiving relatively constant colors when objects are lit by different illuminants.4 The illuminant estimation is an ill-posed problem,5 and it is one of the most delicate modules of the entire image processing pipeline. Numerous methods exist in the literature, and excellent reviews of them can be found in the works of Hordley,4 Bianco et al.,6 and Gijsenij et al.7 A recent research area, which has shown promising results, aims to improve illuminant estimation by using visual information automatically extracted from the images. The existing algorithms exploit both low-level,8,9 intermediate-level,10 and high-level11,12 visual information. The second stage of the color correction pipeline transforms the image data into a standard color space. This transformation, usually called color matrixing, is needed because the spectral sensitivity functions of the sensor color channels rarely match those of the desired output color space. This transformation is usually performed by using a linear transformation matrix, and it is optimized assuming that the illuminant in the scene has been successfully estimated and compensated for Refs. 13 and 14. Both the illuminant estimation process and the color correction matrix concur in the formation of the overall perceived image quality. These two processes have always been studied and optimized separately, thus ignoring the interactions between them with the only exception (to the best of our knowledge) of the authors that have investigated their interactions and how to optimize them for the overall color accuracy on datasets synthetically generated.6 Nevertheless many factors on real systems can affect the color fidelity, e.g., noise, limited dynamic range, and signal degradation due to digital signal processing. This work aims to design and test new and more robust color correction pipelines. The first module exploits different illuminant estimation and correction algorithms that are automatically selected on the basis of the image content. The second module, taking into account the behavior of the first module, makes it possible to alleviate error propagation and improve color rendition accuracy. The proposed pipelines are tested and compared with state of the art solutions on a publicly available dataset of RAW images.15 Experimental results show that illuminant estimation algorithms exploiting visual information extracted from the images, and taking into account the cross-talks between the modules of the pipeline can significantly improve color rendition accuracy. 2.Image FormationAn image acquired by a digital camera can be represented as a function mainly dependent on three physical factors: the illuminant spectral power distribution , the surface spectral reflectance , and the sensor spectral sensitivities . Using this notation, the sensor responses at the pixel with coordinates can be thus described as where is the wavelength range of the visible light spectrum, and are three-component vectors. Since the three sensor spectral sensitivities are usually more sensitive, respectively to the low, medium, and high wavelengths, the three-component vector of sensor responses is also referred to as the sensor or camera raw triplet. In the following, we adopt the convention that RGB triplets are represented by column vectors.In order to render the acquired image as close as possible to what a human observer would perceive if placed in the original scene, the first stage of the color correction pipeline aims to emulate the color constancy feature of the HVS, i.e., the ability to perceive relatively constant colors when objects are lit by different illuminants. The dedicated module is usually referred to as automatic white balance (AWB), which should be able to determine from the image content the color temperature of the ambient light and compensate for its effects. Numerous methods exist in the literature, and Hordley,4 Bianco et al.,6 and Gijsenij et al.7 give an excellent review of them. Once the color temperature of the ambient light has been estimated, the compensation for its effects is generally based on the Von Kries hypothesis,16 which states that color constancy is an independent regulation of the three cone signals through three different gain coefficients. This correction can be easily implemented on digital devices as a diagonal matrix multiplication. The second stage of the color correction pipeline transforms the image data into a standard RGB (e.g., sRGB, ITU-R BT.709) color space. This transformation, usually called color matrixing, is needed because the spectral sensitivity functions of the sensor color channels rarely match those of the desired output color space. Typically this transformation is a matrix with nine variables to be optimally determined, and there are both algebraic13 and optimization-based methods14,16 to find it. The typical color correction pipeline can be thus described as follows: where are the camera raw RGB values, is an exposure compensation common gain, the diagonal matrix is the channel-independent gain compensation of the illuminant, the full matrix , is the color space conversion transform from the device-dependent RGB to the sRGB color space, is the gamma correction defined for the sRGB color space, and are the output sRGB values. The exponent is intended here, with abuse of notation, to be applied to every element of the matrix.The color correction pipeline is usually composed of a fixed white balance algorithm, coupled with a color matrix transform optimized for a single illuminant. 3.Proposed ApproachIn this work, since it has previously been shown5 that within a set of AWB algorithms, the best and the worst ones do not exist, but they change on the basis of the image characteristic, we consider a set of single AWB algorithms,17 and two classification-based modules,10,8 able to identify the best AWB algorithm to use for each image exploiting automatically extracted information about the image class or image content in terms of low-level features. For what concerns the matrix transform module, we consider together with a single matrix optimized for a single illuminant a module based on multiple matrices optimized for different illuminants, and we consider matrices optimized taking into account the AWB algorithm behavior.6 3.1.Automatic White Balance ModulesThe first AWB module considered is the best single (BS) algorithm extracted from the ones proposed by Van de Weijer et al.17 They unified a variety of color constancy algorithms in a unique framework. The different algorithms estimate the color of the illuminant by implementing instantiations of the following equation: where is the order of the derivative, is the Minkowski norm, is the convolution of the image with a Gaussian filter with scale parameter , and is a constant to be chosen so that the illuminant color has unit length. Varying the three variables , it is possible to generate six algorithm instantiations that correspond with well-known and widely used color constancy algorithms. The six different instantiations used in this work are reported in Table 1, together with their underlying assumptions.Table 1Color constancy algorithms that can be generated as instantiations of Eq. (3), together with their underlying hypothesis.
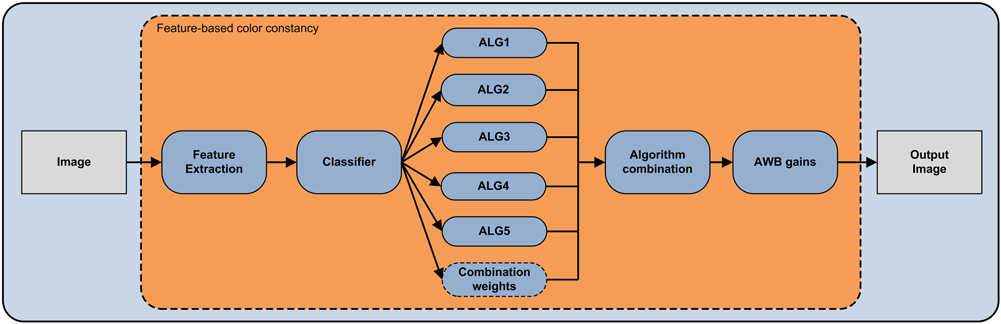
The different AWB instances have been optimized on the dataset proposed by Ciurea and Funt,18 and the best performing one on an independent training set is selected as the BS algorithm.10 The optimal parameters found are reported in Table 1. The second AWB module considered is the class based (CB) algorithm extracted from Ref. 10. It adopts a classification step to assign each image to indoor, outdoor, or ambiguous classes. The classifier, which is described below, is trained on general purpose, low-level features automatically extracted from the images: color histogram, edge direction histogram, statistics on the wavelet coefficients, and color moments (see Ref. 10 for a more detailed description of them). A different AWB algorithm is associated to each of the three possible classes: on the basis of the classification result, only the corresponding AWB algorithm selected is applied. The strategy for the selection and the tuning of the most appropriate algorithm (or combination of algorithms) for each class is fully described.10 The block diagram of the CB algorithm is reported in Fig. 1. The third module considered is the feature based (FB) algorithm extracted from Ref. 8. It is based on five independent AWB algorithms and a classification step that automatically selects which AWB algorithm to use for each image. It is also possible to use the output of the classifier as weights to combine the estimations of the different algorithms considered.5,19 The classifier is trained on low-level features automatically extracted from the images. The feature set includes the general purpose features used for the CB algorithm and some features specifically designed. These features are the number of different colors, the percentage of color components that are clipped to the highest and lowest value that can be represented in the image color space, the magnitudes of the edges, and a cast index representing the extent of the presence of a color cast in the image (inspired by the work done in Ref. 20). See Ref. 8 for a detailed description of the features. The block diagram of the FB algorithm is reported in Fig. 2. The CB and FB AWB modules share the same classification strategy. They use tree classifiers constructed according to the CART methodology.21 Briefly, tree classifiers are classifiers produced by recursively partitioning the predictors space, each split being formed by conditions related to the predictors values. In tree terminology, subsets are called nodes: the predictors space is the root node, terminal subsets are terminal nodes, and so on. Once a tree has been constructed, a class is assigned to each of the terminal nodes, and when a new case is processed by the tree, its predicted class is the class associated with the terminal node into which the case finally moves on the basis of its predictors values. The construction process is based on training sets of cases of known class. Tree classifiers compare well with other consolidated classifiers. Many simulation studies have shown their accuracy to be very good, often close to the achievable optimum.21 Moreover, they provide a clear understanding of the conditions that drive the classification process. Finally, they imply no distributional assumptions for the predictors and can handle both quantitative and qualitative predictors in a natural way. Since in high dimensional and complex problems, as is the case here, it is practically impossible to obtain in one step good results in terms of accuracy, no matter how powerful the chosen class of classifiers is, we decided to perform the classification by also using what is called a “perturbing and combining” method.22,23 Methods of this kind, which generate in various ways multiple versions of a base classifier and use these to derive an aggregate classifier, have proved successful in improving accuracy. We used bagging (bootstrap aggregating), since it is particularly effective when the classifiers are unstable, as trees are; that is, when small perturbations in the training sets, or in the construction process of the classifiers, may result in significant changes in the resulting prediction. With bagging the multiple versions of the base classifier are formed by making bootstrap replicates of the training set and using them as new training sets. The aggregation is made by majority vote. In any particular bootstrap replicate, each element of the training set may appear repeated, or not at all, since the replicates are obtained by resampling with replacement. To provide a measure of confidence in the classification results and, still, greater accuracy, we applied an ambiguity rejection rule24 to the bagged classifier: the classification obtained by means of the majority vote is rejected if the percentage of trees that contribute to it is lower than a given threshold. In this way only those results to which the classifier assigns a given confidence, as set by the threshold, are accepted. 3.2.Color Matrix Transform ModulesThe color matrix transform modules considered are extracted from the strategies proposed by the authors in Ref. 6. In the following a more compact version of Eq. (2) is used: where , and , respectively represent the exposure compensation gain, the diagonal matrix for the illuminant compensation and the color matrix transformation.The first color matrix transform module considered is named Single ILLuminant (SILL) since it is based on a single matrix transform optimized for a single illuminant. Given a set of different patches whose sRGB values are known, and the corresponding camera raw values measured by the sensor when the patches are lit by the chosen illuminant, what is usually done is to find the matrix that satisfies where is the chosen error metric, and the subscript indicates the triplet in the ’th column of the matrix, i.e., it indicates the tri-chromatic values of the ’th patch. In this work, the error metric adopted is the average colorimetric error between the reference and calculated sRGB values mapped in the CIEL*a*b* color space. The values of and have been previously computed in order to perfectly expose the scene and compensate for the illuminant. Given the importance of neutral tones in the color reproduction, the 9 deg of freedom of the color matrix transformation are usually reduced to six by a white point preserving constraint, i.e., a neutral color in the device-dependent color space should be mapped to a neutral color in the device independent color space. This can be easily obtained by constraining each row to sum to one.The second color matrix transform module considered is named multiple illuminant (MILL). It differs from the first module since it is based on multiple matrix transforms, with each one optimized for a different illuminant by using Eq. (5). Therefore for each image a different matrix transform is used. First of all the AWB algorithm is applied to estimate the illuminant compensation gains, then the two training illuminants and with the most similar gains are identified, and the matrix transform is calculated as follows: where and is the angular error between the gains considered, i.e.,The reference illuminants could be a set of predefined standard illuminants (as done in Ref. 6), or it could be found by clustering the ground truth illuminants of the images in the training set. Then, for each centroid of the clusters found, the best color correction matrix is computed. The latter approach is here adopted as described in Sec. 5. The third color matrix transform module considered is named SILL with white balance error buffer (SILLWEB). It is based on a single matrix transform optimized for a single illuminant, taking into account the behavior of the AWB module used. Suppose the best gain coefficients have already been determined and reshaped in the diagonal transform to compensate the considered illuminant; we then generate a set of gain coefficients with different distances from , measured using the error metric. These can be used to simulate errors that may occur in the AWB process and are paired with a weights distribution that reflects the frequency of the considered errors. The optimization problem can be thus formulated as where , are the diagonal matrices obtained, respectively, by reshaping the gain coefficients .The fourth color matrix transform module considered is named MILL with white balance error buffer (MILLWEB). It differs from the third module since it is based on multiple matrix transforms, with each one optimized for a different taking illuminant using Eq. (9). For each image a different matrix transform is used. First the AWB algorithm is applied to estimate the illuminant compensation gains, then the two training illuminants and with the most similar gains are identified, and the matrix transform is calculated as in Eqs. (6) and (7). All the matrices for the different color matrix transform modules are found by optimization using the pattern search method (PSM). PSMs are a class of direct search methods for nonlinear optimization.25 PSMs are simple to implement and do not require any explicit estimate of derivatives. Furthermore, global convergence can be established under certain regularity assumptions of the function to minimize.26 The general form of a PSM is reported in Table 2, where is the function to be minimized, is the iteration number, is the current best solution, is the set of search directions, and is a step-length parameter. Table 2Pseudo-code of the general form of a pattern search method (PSM).
4.Experimental SetupThe aim of this section is to investigate how the proposed methods can be combined in order to design a new color correction pipeline. In particular, we investigate the color accuracy improvement that the illuminant estimation algorithms of Sec. 3 and the color space conversion strategies of Sec. 4 can give when they are used individually and combined properly. 4.1.Image Dataset and Evaluation ProcedureTo test the performance of the investigated processing pipelines, a standard dataset of RAW camera images having a known color target is used.15 This dataset is captured using a high-quality digital SLR camera in RAW format and is therefore free of any color correction. This dataset was originally available in sRGB-format, but Shi and Funt27 reprocessed the raw data to obtain linear images with a higher dynamic range (12 bits as opposed to standard 8 bits). The dataset consists of a total of 568 images. The Macbeth ColorChecker (MCC) chart is included in every scene acquired, and this allows us to estimate accurately the actual illuminant of each acquired image.27 Some examples from the image dataset are shown in Fig. 3. The spatial coordinates of the MCC in each image of the dataset have been automatically detected28 and manually refined. The flowchart of the evaluation procedure adopted is given in Fig. 4, where it can be seen that the only step in which the MCC chart is cropped is the illuminant estimation one. Fig. 4Pipeline evaluation: the Macbeth ColorChecker (MCC) is localized and masked; the illuminant is estimated on the image with the masked MCC, and the unmasked image is illuminant-corrected on the basis of this estimate; the color correction matrix is then applied to this image, the RGB coordinates of the MCC are extracted and compared with the MCC theoretical ones.  The investigated illuminant estimation algorithms described in Sec. 3 have been individually applied to the images of the dataset, excluding the MCC chart regions that have been previously cropped. Given these estimations, the illuminant corrections are then performed on the whole images (therefore also including the MCC chart). The color matrix transformations found according to the computational strategies described in Sec. 4 are then applied to the whole, white balanced images. For each processed image, the MCC chart is then extracted, and the average RGB values of the central area of each patch are calculated. The color rendition accuracy of the pipeline is measured in terms of average error between the CIEL*a*b* color coordinates of the color corrected MCC patches, and their theoretical CIEL*a*b* values that are computed using standard equations from their theoretical RGB values. 5.Pipeline Training and TestingIn this section the color correction pipelines composed of the combination of the modules for the illuminant estimation algorithms of Sec. 3 and the color matrix transform modules of Sec. 4 are tested. Globally, 20 different pipelines have been tested; they are generated as an exhaustive combination of the modules proposed. The acronyms of the proposed strategies are generated using the scheme reported in Fig. 5. The first part indicates the typology of AWB used (: the BS AWB algorithm among the general purpose ones considered in Ref. 10 is used; : the algorithm described in Ref. 10, based on an indoor-outdoor classification is used; : the algorithm described in Ref. 8 is used, which is based on five independent AWB algorithms and a classification step that automatically selects which AWB algorithm to use for each image). The second part indicates the number and type of the color correction matrix used (: single matrix optimized for a fixed single illuminant, : multiple matrices each optimized for a different single illuminant). The third part indicates if the strategy implements color correction matrices able to compensate for AWB errors () or not (0). The last part indicates if a real classifier has been used in the AWB module (0) or manual classification (ideal). The symbol 0 is reported in the scheme but is intended as the null character and thus omitted in the acronyms generated. Since the considered modules need a training phase, 30% of the images in the dataset were randomly selected and used as training set; the remaining 70% were used as test set. For the strategies that are based on multiple color correction matrices, these are computed by first clustering the ground truth illuminants of the images in the training set into seven different clusters using a -means algorithm.29 Then, for each centroid of the clusters found, the best color correction matrix is calculated. 6.Experimental ResultsThe average over the test images of the average colorimetric errors obtained by the tested pipelines on the MCCs are computed and reported in Table 3. The average of the maximum colorimetric error are also reported. For both the error statistics the percentage improvement over the baseline method, i.e., BS-SILL pipeline, are reported. The results of the pipelines tested are clustered into four different groups depending on the color correction strategy adopted. Table 3Color correction pipeline accuracy comparison.
To understand if the differences in performance among the pipelines considered are statistically significant, we have used the Wilcoxon signed-rank test.30 This statistical test permits comparison of the whole error distributions without limiting to punctual statistics. Furthermore, it is well suited because it does not make any assumptions about the underlying error distributions, and it is easy to find, using for example the Lilliefors test,31 that the assumption about the normality of the error distributions does not always hold. Let and be random variables representing the errors obtained on the MCCs of all test images by two different pipelines. Let and be the median values of such random variables. The Wilcoxon signed-rank test can be used to test the null hypothesis against the alternative hypothesis . We can test against at a given significance level . We reject and accept if the probability of observing the error differences we obtained is less than or equal to . We have used the alternative hypothesis with a significance level . Comparing the error distributions of each pipeline with all the others gives the results reported in Table 4. A “+” sign in the position of the table means that the error distribution obtained with the pipeline has been considered statistically better than that obtained with the pipeline ; a “−” sign that it has been considered statistically worse, and a “=“ sign that they have been considered statistically equivalent. Table 4Wilcoxon signed rank test results on the error distributions obtained by the different pipelines. A “+” sign in the (i, j)-position means that the error distribution obtained with the pipeline i has been considered statistically better than that obtained with the pipeline j, a “−” sign that it has been considered statistically worse, and an “=” sign that they have been considered statistically equivalent.
It is possible to note in Table 3 that in all the groups of pipelines proposed (groups that share the same color correction matrix strategy, i.e., SILL, MILL, SILLWEB, and MILLWEB), the use of the FB AWB leads to a higher color-rendition accuracy with respect to the use of the CB AWB and of the BS AWB. It is interesting to notice that significant improvements in the color rendition accuracy can be achieved even if the classifiers used for the feature and CB AWB strategies are not optimal. Analyzing the behavior of the pipelines sharing the same AWB strategy, it is possible to notice that the results of Ref. 6 are also confirmed. In fact, the multiple illuminant color correction (MILL) performs better than the single illuminant one (SILL). The single illuminant color correction, which is optimized taking into account the statistics of how the AWB algorithm tends to make errors (SILLWEB), performs better than the multiple illuminant color correction (MILL). Finally, the multiple illuminant color correction with white balance error buffer (MILLWEB) performs better than the corresponding single illuminant instantiation (SILLWEB). For what concerns the best pipeline proposed, which is the FB-MILLWEB, it can be observed that when using the ideal classifier, 48% of improvement (from 0% to 14.15% with respect to the benchmarking pipeline) is due to the use of the MILLWEB color correction matrix approach and the remaining 52% (from 14.15% to 29.32% with respect to the benchmarking pipeline) to the FB AWB approach. When using the real classifier the remaining part to the FB AWB approach. This can be considered a lower bound of the pipeline performance, since, as already explained before, the classifier used is not optimal for the image database used. In Fig. 6 the workflow of the best performing pipeline proposed, i.e., the FB-MILLWEB, is reported. The low-level features considered are extracted from the RAW image and fed to the classifier, which as output gives the weights to use for the linear combination of the five simple AWB algorithms considered. The AWB correction gains given by the five simple AWB algorithms considered are then combined to give the AWB correction gains to use. The image is then corrected with these gains to obtain an AWB corrected image. The correction gains are used to identify the two training illuminants most similar to the estimated one. The two color correction matrices computed for the two identified illuminants are retrieved and combined accordingly to the illuminant similarity. The image is finally color corrected using this color correction matrix. Fig. 6Workflow of the pipeline composed of the feature-based (FB) automatic white balance (AWB) and the multiple illuminant color matrixing with white balance error buffer (FB-MILLWEB).  In Fig. 7 it is shown the image on which the best pipeline proposed, i.e., FB-MILLWEB, makes the larger color error. For sake of comparison, the results obtained with BS-SILL (a); FB-SILL (b); FB-SILLWEB (c); and FB-MILLWEB (d) pipelines are also shown. Finally in Fig. 7(e) the best achievable results is reported, which is computed using the achromatic patches of the MCC to estimate the ideal AWB gains, and the color space transformation has been optimized specifically for this image. Taking into account that the image reproduction may have altered the image content, making the differences between the different pipelines not clearly appreciable, we report in Fig. 8 the error distribution between the ideal color-corrected image [Fig. 7(e)] and the output of the tested pipelines. The images reported in Fig. 7(a)–7(d) are therefore converted in CIEL*a*b* color coordinates and the colorimetric error is computed for every pixel of each image with respect to the ideal image. The histograms of the colorimetric errors are, respectively reported in Fig. 8(a)–8(d). To compare the color error distributions of the pipelines considered on this image, we use the Wilcoxon signed-rank test. The output of the test is reported in Table 5. It is possible to notice that even in the worst case example, the FB-MILLWEB pipeline, which is the best on the whole dataset, is still the best one. Fig. 7Worst case example. The results obtained by different pipelines are reported: BS-SILL (a); FB-SILL (b); FB-SILLWEB (c); FB-MILLWEB (d); and ideal correction (e).  Fig. 8Histograms of the colorimetric error for the images reported in Figs. 7(a)–(d), using Figs. 7(e) as reference.  Table 5Wilcoxon signed rank test results on the error distributions obtained by the different pipelines on the worst case example.
7.ConclusionDigital camera sensors are not perfect and do not encode colors the same way in which the human eye does. A processing pipeline is thus needed to convert the RAW image acquired by the camera to a representation of the original scene that should be as faithful as possible. In this work we have designed and tested new color correction pipelines, which exploit the cross-talks between its modules in order to lead to a higher color rendition accuracy. The effectiveness of the proposed pipelines is shown on a publicly available dataset of RAW images. The experimental results show that in all the groups of pipelines proposed (groups that share the same color correction matrix strategy, i.e., SILL, MILL, SILLWEB, and MILLWEB), the use of the FB AWB leads to a higher color-rendition accuracy when compared with the use of the CB AWB and of the BS AWB. It is interesting to note that significant improvements in the color-rendition accuracy can be achieved even if the classifiers used for the feature and CB AWB strategies are not optimal. Analyzing the behavior of the pipelines sharing the same AWB strategy, it is possible to note that the results of Ref. 6 are also confirmed. In fact the multiple illuminant color correction (MILL) performs better than the single illuminant one (SILL). The single illuminant color correction, which is optimized taking into account the statistics of how the AWB algorithm tends to make errors (SILLWEB), performs better than the multiple illuminant color correction (MILL). Finally, the multiple illuminant color correction with white balance error buffer (MILLWEB) performs better than the corresponding single illuminant instantiation (SILLWEB). The present work makes it also possible to identify some open issues that must be addressed in the future. Illuminant estimation algorithms are generally based on the simplifying assumption that the spectral distribution of a light source is uniform across scenes. However, in reality, this assumption is often violated due to the presence of multiple light sources.32 Some multiple illuminant estimation algorithms have been proposed;33 however, they assume very simple setups, or a knowledge of the number and color of the illuminants.34 Once the scene illuminant has been estimated, the scene is usually corrected in the RGB device dependent color space using the diagonal Von Kries model.16 Several studies have investigated the use of different color spaces for the illuminant correction35,36 as well as nondiagonal models.37 A different approach could be to use chromatic adaptation transforms38,39 to correct the scene illuminant. As suggested by a reviewer, the use of larger color correction matrices should be investigated, taking into account not only color rendition accuracy, but also noise amplification in particular on dark colors. ReferencesR. Ramanathet al.,
“Color image processing pipeline,”
IEEE Signal Proc. Mag., 22
(1), 34
–43
(2005). http://dx.doi.org/10.1109/MSP.2005.1407713 ISPRE6 1053-5888 Google Scholar
C. Weerasingheet al.,
“Novel color processing architecture for digital cameras with CMOS image sensors,”
IEEE Trans. Consum. Electron., 51
(4), 1092
–1098
(2005). http://dx.doi.org/10.1109/TCE.2005.1561829 ITCEDA 0098-3063 Google Scholar
W.-C. Kaoet al.,
“Design consideration of color image processing pipeline for digital cameras,”
IEEE Trans. Consum. Electron., 52
(4), 1144
–1152
(2006). http://dx.doi.org/10.1109/TCE.2006.273126 ITCEDA 0098-3063 Google Scholar
S. D. Hordley,
“Scene illuminant estimation: past, present, and future,”
Color Res. Appl., 31
(4), 303
–314
(2006). http://dx.doi.org/10.1002/(ISSN)1520-6378 CREADU 0361-2317 Google Scholar
S. BiancoF. GaspariniR. Schettini,
“Consensus based framework for illuminant chromaticity estimation,”
J. Electron. Imag., 17
(2), 023013
(2008). http://dx.doi.org/10.1117/1.2921013 JEIME5 1017-9909 Google Scholar
S. Biancoet al.,
“Color space transformations for digital photography exploiting information about the illuminant estimation process,”
J. Opt. Soc. Am. A, 29
(3), 374
–384
(2012). http://dx.doi.org/10.1364/JOSAA.29.000374 JOAOD6 0740-3232 Google Scholar
A. GijsenijT. GeversJ. van de Weijer,
“Computational color constancy: survey and experiments,”
IEEE Trans. Image Proc., 20
(9), 2475
–2489
(2011). http://dx.doi.org/10.1109/TIP.2011.2118224 IIPRE4 1057-7149 Google Scholar
S. Biancoet al.,
“Automatic color constancy algorithm selection and combination,”
Pattern Recogn., 43
(3), 695
–705
(2010). http://dx.doi.org/10.1016/j.patcog.2009.08.007 PTNRA8 0031-3203 Google Scholar
A. GijsenijT. Gevers,
“Color constancy using natural image statistics and scene semantics,”
IEEE Trans. Pattern Anal. Mach. Intell., 33
(4), 687
–698
(2011). http://dx.doi.org/10.1109/TPAMI.2010.93 ITPIDJ 0162-8828 Google Scholar
S. Biancoet al.,
“Improving color constancy using indoor-outdoor image classification,”
IEEE Trans. Image Proc., 17
(12), 2381
–2392
(2008). http://dx.doi.org/10.1109/TIP.2008.2006661 IIPRE4 1057-7149 Google Scholar
J. van de WeijerC. SchmidJ. Verbeek,
“Using high-level visual information for color constancy,”
in Proc. IEEE 14th Int. Conf. on Computer Vision,
1
–8
(2007). Google Scholar
S. BiancoR. Schettini,
“Color constancy using faces,”
in Proc. IEEE Conf. Computer Vision and Pattern Recognit.,
65
–72
(2012). Google Scholar
P. M. Hubelet al.,
“Matrix calculations for digital photography,”
in Proc. 5th Color Imaging Conf.: Color Science, Systems and Applications,
105
–111
(1997). Google Scholar
S. Biancoet al.,
“A new method for RGB to XYZ transformation based on pattern search optimization,”
IEEE Trans. Consum. Electron., 53
(3), 1020
–1028
(2007). http://dx.doi.org/10.1109/TCE.2007.4341581 ITCEDA 0098-3063 Google Scholar
P. V. Gehleret al.,
“Bayesian color constancy revisited,”
in Proc. IEEE Computer Society Conf. on Computer Vision and Pattern Recognit.,
1
–8
(2008). Google Scholar
J. von Kries, Chromatic Adaptation, Festschrift der Albrecht-Ludwig-Universitat, Fribourg
(1902). Google Scholar
D. L. MacAdam, Sources of Color Science, MIT Press, Cambridge
(1970). Google Scholar
J. van de WeijerT. GeversA. Gijsenij,
“Edge-based color constancy,”
IEEE Trans. Image Proc., 16
(9), 2207
–2214
(2007). http://dx.doi.org/10.1109/TIP.2007.901808 IIPRE4 1057-7149 Google Scholar
F. CiureaB. Funt,
“A large image database for color constancy research,”
in Proc. IS&T/SID 11th Color Imaging Conf.,
160
–164
(2003). Google Scholar
S. BiancoF. GaspariniR. Schettini,
“Combining strategies for white balance,”
Proc. SPIE, 6502 65020D
(2007). http://dx.doi.org/10.1117/12.705190 PSISDG 0277-786X Google Scholar
F. GaspariniR. Schettini,
“Color balancing of digital photos using simple image statistics,”
Pattern Recogn., 37
(6), 1201
–1217
(2004). http://dx.doi.org/10.1016/j.patcog.2003.12.007 PTNRA8 0031-3203 Google Scholar
L. Breimanet al., Classification and Regression Trees, Wadsworth and Brooks/Cole, Belmont, California
(1984). Google Scholar
L. Breiman,
“Bagging predictors,”
Mach. Learn., 26
(2), 123
–140
(1996). MALEEZ 0885-6125 Google Scholar
L. Breiman,
“Arcing classifiers,”
Ann. Stat., 26
(3), 801
–849
(1998). http://dx.doi.org/10.1214/aos/1024691079 ASTSC7 0090-5364 Google Scholar
A. VailayaA. Jain,
“Reject option for VQ-based Bayesian classification,”
in Proc. 15th Int. Conf. Pattern Recognit.,
48
–51
(2000). Google Scholar
R. M. LewisV. Torczon,
“Pattern search methods for linearly constrained minimization,”
SIAM J. Optim., 10
(3), 917
–941
(2000). http://dx.doi.org/10.1137/S1052623497331373 SJOPE8 1095-7189 Google Scholar
R. M. LewisV. Torczon,
“On the convergence of pattern search algorithms,”
SIAM J. Optim, 7
(1), 1
–25
(1997). http://dx.doi.org/10.1137/S1052623493250780 SJOPE8 1095-7189 Google Scholar
S. BiancoC. Cusano,
“Color target localization under varying illumination conditions,”
in Proc. 3rd Int. Workshop on Computational Color Imaging,
245
–255
(2011). Google Scholar
J. A. HartiganM. A. Wong,
“Algorithm AS136: A k-means clustering algorithm,”
Appl. Stat., 28 100
–108
(1979). http://dx.doi.org/10.2307/2346830 Google Scholar
F. Wilcoxon,
“Individual comparisons by ranking methods,”
Biometrics, 1
(6), 80
–83
(1945). http://dx.doi.org/10.2307/3001968 BIOMB6 0006-341X Google Scholar
H. Lilliefors,
“On the Kolmogorov-Smirnov test for normality with mean and variance unknown,”
J. Am. Stat. Assoc., 62
(318), 399
–402
(1967). http://dx.doi.org/10.1080/01621459.1967.10482916 JSTNAL 0003-1291 Google Scholar
A. GijsenijR. LuT. Gevers,
“Color constancy for multiple light sources,”
IEEE Trans. Image Proc., 21
(2), 697
–707
(2012). http://dx.doi.org/10.1109/TIP.2011.2165219 IIPRE4 1057-7149 Google Scholar
M. Ebner, Color Constancy, John Wiley & Sons, England
(2007). Google Scholar
E. Hsuet al.,
“Light mixture estimation for spatially varying white balance,”
in Proc. ACM SIGGRAPH,
(2008). Google Scholar
K. BarnardF. CiureaB. Funt,
“Sensor sharpening for computational color constancy,”
J. Opt. Soc. Am. A, 18
(11), 2728
–2743
(2001). http://dx.doi.org/10.1364/JOSAA.18.002728 JOAOD6 0740-3232 Google Scholar
F. Xiaoet al.,
“Preferred color spaces for white balancing,”
Proc. SPIE, 5017 342
–350
(2003). http://dx.doi.org/10.1117/12.478482 PSISDG 0277-786X Google Scholar
B. FuntH. Jiang,
“Nondiagonal color correction,”
in Proc. Int. Conf. Image Process.,
481
–484
(2003). Google Scholar
“A review of chromatic adaptation transforms,”
(2004). Google Scholar
S. BiancoR. Schettini,
“Two new von Kries based chromatic adaptation transforms found by numerical optimization,”
Color Res. App., 35
(3), 184
–192
(2010). http://dx.doi.org/10.1002/col.v35:3 CREADU 0361-2317 Google Scholar
Biography Simone Bianco obtained a PhD in computer science at DISCo (Dipartimento di Informatica, Sistemistica e Comunicazione) of the University of Milano-Bicocca, Italy, in 2010. He obtained BSc and the MSc degrees in mathematics from the University of Milano-Bicocca, Italy, respectively, in 2003 and 2006. He is currently a postdoc working on image processing. The main topics of his current research concern digital still cameras processing pipelines, color space conversions, optimization techniques, and characterization of imaging devices.  Arcangelo R. Bruna received a master’s degree from Palermo University, Italy, in 1998. He works for ST Microelectronics, and his research interests are in the area of image processing (noise reduction, auto white balance, video stabilization, etc.) and computer vision algorithms (visual search). He is also currently involved in the MPEG-CDVS (compact descriptors for visual search) standardization.  Filippo Naccari received his MS Italian degree in electronic engineering at University of Palermo, Italy. Since July 2002, he has been working at STMicroelectronics as researcher at the Advanced System Technology, Computer Vision Group, Catania Lab, Italy. His research interests are in the field of digital color and image processing, color constancy, and digital images coding.  Raimondo Schettini is a professor at the University of Milano Bicocca (Italy). He is vice director of the Department of Informatics, Systems and Communication, and head of Imaging and Vision Lab ( www.ivl.disco.unimib.it). He has been associated with Italian National Research Council (CNR) since 1987 where he has headed the Color Imaging lab from 1990 to 2002. He has been team leader in several research projects and published more than 250 reference papers and six patents about color reproduction and image processing, analysis, and classification. He has been recently elected fellow of the International Association of Pattern Recognition (IAPR) for his contributions to pattern recognition research and color image analysis. |