|
|
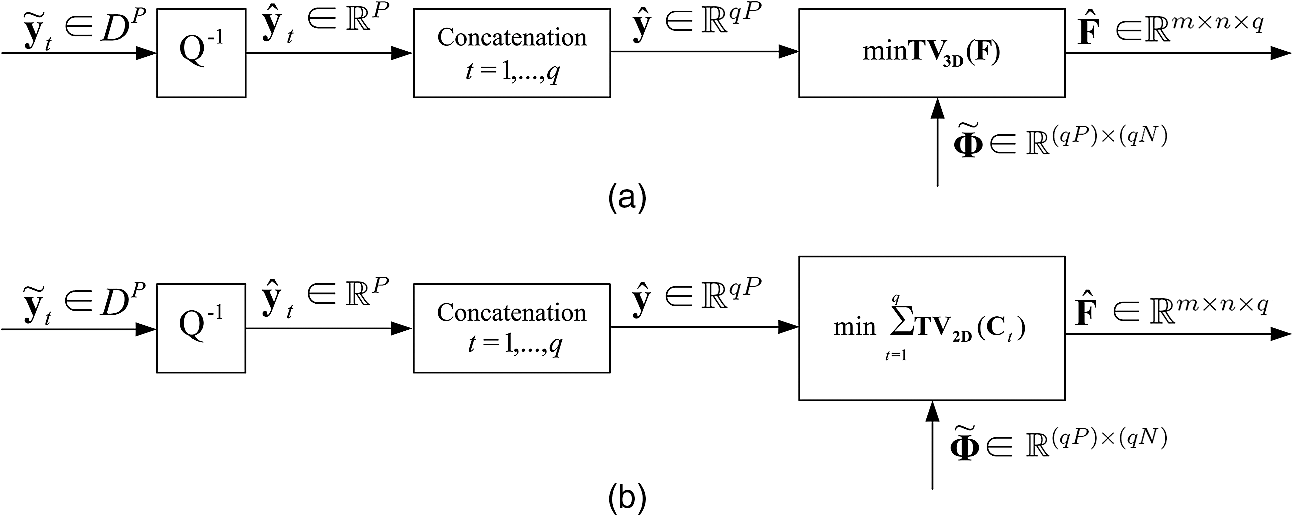
1.IntroductionBy the Nyquist–Shannon sampling theory, to reconstruct a signal without error, the sampling rate must be at least twice the highest frequency of the signal. Compressive sampling (CS), also known as compressed sensing, is an emerging line of work that suggests sub-Nyquist sampling of sparse signals of interest.1–3 Rather than collecting an entire Nyquist ensemble of signal samples, CS can reconstruct sparse signals from a small number of (random3 or deterministic4) linear measurements via convex optimization,5 linear regression,6,7 or greedy recovery algorithms.8 An example of a CS application that has attracted interest is the “single-pixel camera” architecture,9 in which a still image can be produced from significantly fewer captured measurements than the number of desired/reconstructed image pixels. A desirable next-step development is compressive video streaming. In the present work, we consider a video transmission system in which the transmitter/encoder performs pure direct compressed sensing acquisition without the benefits of the familiar sophisticated forms of video encoding. This setup is of interest, for example, in problems that involve large wireless multimedia networks of primitive low-complexity, power-limited video sensors. CS is potentially an enabling technology in this context,10 as video acquisition would require minimal or no computational power at all, yet transmission bandwidth would still be greatly reduced. In such a case, the burden of quality video reconstruction will fall solely on the receiver/decoder side. In comparison, conventional predictive encoding schemes [H.26411 or high efficiency video coding (HEVC)12] are known to offer great transmission bandwidth savings for targeted video quality levels, but place strong complexity and power consumption demands on the encoder side. The transmission bandwidth and the quality of the reconstructed CS video are determined by the number of collected measurements, which based on CS principles should be proportional to the sparsity level of the signal. The challenge of implementing a well-compressed and well-reconstructed CS-based video streaming system rests on developing effective sparse representations and corresponding video recovery algorithms. Several methods for CS video recovery have already been proposed, each relying on a different sparse representation. An intuitive (JPEG-motivated) approach is to independently recover each frame using the two-dimensional discrete cosine transform (2D-DCT)13 or a two-dimensional discrete wavelet transform (2D-DWT).14 As an improvement that enhances sparsity by exploiting correlations among successive frames, several frames can be jointly recovered under a three-dimensional DWT (3D-DWT)14 or 2D-DWT applied on inter-frame difference data.15 To enhance sparse representation and exploit motion among successive video frames, a video sequence is divided into key frames and CS frames in Refs. 16 and 17. Whereas each key frame is reconstructed individually using a fixed basis (e.g., 2D-DWT or 2D-DCT), each CS frame is reconstructed conditionally using an adaptively generated basis from adjacent already reconstructed key frames. In Refs. 18–20, each frame of a compressed-sensed video sequence is reconstructed iteratively using adaptively generated Karhunen–Loève transform (KLT) bases from neighboring frames. Another approach for compressed-sensed signal recovery is total-variation (TV) minimization. TV minimization, also known as TV regularization, has been widely used in the past as an image denoising algorithm.21,22 Based on the principle that signals with excessive, likely spurious detail have excessively high TV (that is, the integral of the absolute gradient of the signal is high), reducing TV of the reconstructed signal while staying consistent with the collected samples removes unwanted detail while preserving important information such as edges. Recently, 2D-TV minimization algorithms were successfully used in CS image recovery.5,23–27 In Refs. 28 and 29, a multiframe CS video encoder was proposed with interframe TV minimization decoding. Although promising, such a system requires complex and expensive spatial-temporal light modulators that make the technique difficult to be implemented in practice. In this present work, we propose a system that consists of a pure framewise CS video encoder in which each video frame is encoded independently using compressive sensing. Such a CS video acquisition system can be directly implemented practically with existing CS imaging technology. At the receiver/decoder, we develop and describe in detail a procedure by which multiple independently encoded video frames are jointly recovered successfully via sliding window–based interframe TV minimization. The rest of this paper is organized as follows. In Sec. 2, we briefly review TV-based CS signal recovery principles. In Sec. 3, the proposed framewise CS video acquisition system with interframe TV minimization decoding is described in detail. Some experimental results are presented and examined in Sec. 4, and a few conclusions are drawn in Sec. 5. 2.Compressive Sampling with TV Minimization ReconstructionIn this section, we briefly review 2-D and 3-D signal acquisition by CS and recovery using sparse gradient constraints (TV minimization). If the signal of interest is a 2-D image and , , represents vectorization of via column concatenation, then CS measurements of are collected in the form of with a linear measurement matrix , . Under the assumption that images are mostly pixelwise smooth in the horizontal and vertical pixel directions, it is natural to consider utilizing the sparsity of the spatial gradient of for CS image reconstruction.5,23–27 If denotes the pixel in the ’th row and ’th column of , the horizontal and vertical gradients at are defined, respectively, as and The discrete spatial gradient of at pixel can be interpreted as the 2D vector and the anisotropic 2D-TV of is simply the sum of the magnitudes of this discrete gradient at every pixel, To reconstruct , we can solve the convex program However, in practical situations the measurement vector may be corrupted by noise. Then, CS acquisition of can be formulated as where is the unknown noise vector bounded by a presumably known power amount , . To recover , we can use 2D-TV minimization as in Eq. (4) with a relaxed constraint in the form ofMoving on now to the needs of the specific CS video work presented in this paper, if the underlying signal is a video signal representing a stack of successive frames , , then concatenating the columns of all results to a length vector . If denotes the pixel at the th row and th column of frame , then the horizontal, vertical, and temporal gradient at can be defined, respectively, as and Correspondingly, the spatial-temporal gradient of at can be interpreted as the 3D vector and the anisotropic 3D-TV of is simply the sum of the magnitudes of this discrete gradient at every pixel: To reconstruct the frame sequence from noiseless measurements, we can solve the convex program The reconstruction of from noisy measurements can be formulated as the 3D-TV decodingIf the individual frames in are highly time-correlated, then a pixelwise temporal DCT generally improves sparsity. As illustrated in Fig. 1, each temporal-length ( for example) vector , , , consisting of the pixels at spatial position across successive frames, can be represented as where is the 1D-DCT basis and is the transform-domain coefficient vector. The resulting coefficient matrix represents the frequency component that remains unchanged over time (dc) and the subsequent coefficient matrices , , represent frequency components of increasing time variability. Because each matrix , , is expected to have small TV, they can be jointly recovered in the form of where stands for pixelwise inverse 1D-DCT. Subsequently, the complete frame sequence can be reconstructed simply as Below, we will refer to this form of interframe CS reconstruction as TV-DCT decoding.3.Proposed CS Video SystemCS-based signal acquisition with TV-based reconstruction, as described in Sec. 2, can be applied to video coding. In Refs. 28 and 29, the video frame sequence is divided into cubes, and each cube consisting of multiple frames is vectorized and compressed-sensed using a large-scale sensing matrix. At the decoder, each cube of video frames is recovered from the received measurements via 3D-TV decoding as in Eq. (10) or via TV-DCT decoding as in Eqs. (12) and (13). However, such a multiframe CS acquisition system requires simultaneous access—hence, some form of temporal storage—to the whole cube of frames, which is impractical and, arguably, defies the core intention of compressed sensing. In this paper, we propose a practical CS video acquisition system that performs pure, direct framewise encoding. In the simple compressive video encoding block diagram shown in Fig. 2, each frame of size , , is viewed as a vectorized column , , . CS is performed by projecting onto a random measurement matrix , where , , is generated by randomly permuting the columns of an order-, and multiple-of-four, Walsh–Hadamard (WH) matrix followed by arbitrary selection of rows from the available WH rows (if , only arbitrary columns are utilized). This class of WH measurement matrices has the advantage of easy implementation (antipodal entries), fast transformation, and satisfactory reconstruction performance, as we will see later on. A richer class of matrices can be found in Refs. 30 and 31. To quantize the elements of the resulting measurement vector (block in Fig. 2), in this work we follow a simple adaptive quantization approach of two codeword lengths. A positive threshold is chosen such that 1% of the elements in have magnitude above . For every measurement vector , 16-bit uniform scalar quantization is used for elements with magnitudes larger than , and 8-bit uniform scalar quantization is used for the remaining elements. The resulting quantized values are then indexed and transmitted to the decoder.To reconstruct the independently encoded CS video frames, a simplistic idea is to recover each frame independently via 2D-TV decoding by Eq. (6). However, such a decoding scheme does not exploit the interframe similarities of a video sequence. We propose, instead, to jointly recover multiple individually encoded CS frames via interframe TV minimization. As shown in Fig. 3, the proposed interframe CS video decoder collects and concatenates a group of dequantized measurement vectors , , to form . Because each individual dequantized vector is in the form of with noise , can be represented as where is the block diagonal matrix is the concatenation of the vectorized frames and is the concatenation of the noise vectors in the form of The decoder then performs 3D-TV decoding on the frames [Fig. 3(a)] byAlthough Eq. (19) may be considered a powerful joint 3D-TV recovery procedure for general 2D CS-acquired video, for highly temporally correlated video frames, better reconstruction quality may be achieved via TV-temporal-DCT decoding [Fig. 3(b)] in the form of can then be reconstructed simply byIn Eqs. (20) and (21), we carried out interframe decoding for each independent group of frames. To further exploit interframe similarities and capture local motion among adjacent groups of frames, we now propose a sliding-window TV-DCT decoder. The concept of such a decoder is depicted in Fig. 4. Initially, the decoder performs TV-DCT decoding on the first (, for example) frames, specified by a decoding window of length [Fig. 4(a)] using the block diagonal matrix with diagonal elements . The reconstructed frames are called , , , [Fig. 4(b)], where represents the ’th reconstruction of the ’th frame. Then, the decoding window shifts one frame to the right, performs TV-DCT decoding on using the matrix with diagonal elements , and produces the reconstructed frames , , , . The decoder continues on with sliding-window TV-DCT decoding until the last group of frames is recovered. Final reconstruction of each frame is executed by taking the average of all different decodings in the form of Compared to the simple (nonsliding-window) TV-DCT decoder of Eqs. (20) and (21), the sliding-window TV-DCT decoder enforces sparsity for any successive frames in the video sequence. Hence, it protects sharp temporal changes for pixels that have fast motion in any -frame-sequence and smooths intensities for static or slow-motion pixels in the same decoding window.4.Experimental ResultsIn this section, we study experimentally the performance of the proposed CS video systems by evaluating the peak signal-to-noise ratio (PSNR) (as well as the perceptual quality) of reconstructed video sequences. Two test sequences, Container and Highway, with CIF resolution pixels and frame rate of , are used. Processing is carried out only on the luminance component. At our trivial, pure CS encoder side, each frame is handled as a vectorized column of length multiplied by a randomized partial WH matrix . The sensing matrix is referred to as varying if it is independently generated to encode each frame and is referred to as fixed if it is generated only once to encode all frames in the video sequence. The elements of the captured -dimensional measurement vector are quantized and then transmitted to the decoder. In our experiments, , 25344, 38016, 50688, 63360 are used to produce the corresponding bit rates of 3071.7, 6143.4, 9215.1, 12287, and 15358 kbps. (Considering the quantization scheme described in Sec. 3 and frame rate 30 fps, the bit rate can be calculated as .) With an Intel i5-2410M 2.30-GHz processor, the encoding time per frame is well within 0.1 s, whereas the H.264/AVC JM reference software programmed in C++ requires about 1.55 s with low-complexity configurations.11 At the decoder side, we chose the TVAL3 software28,29 for reconstruction motivated by its low-complexity and satisfactory recovery performance characteristics. In our experimental studies for the slow-motion Container sequence, five CS video systems are examined: (1) baseline fixed acquisition with frame-by-frame 2D-TV decoding [Eq. (6)]; (2) fixed and (3) varying acquisition with TV-DCT decoding [Eqs. (20) and (21)]; (4) 3D-TV decoding with fixed [Eq. (19)]; and (5) varying acquisition with sliding-window TV-DCT decoding [Eqs. (20), (21), and (22)]. For the fast-motion Highway sequence, we show results with fixed for CS acquisition and (1) baseline 2D-TV decoding [Eq. (6)]; (2) 3D-TV decoding [Eq. (19)]; (3) plain TV-DCT decoder [Eqs. (20) and (21)]; and (4) sliding-window TV-DCT decoder [Eqs. (20), (21), and (22)]. For all interframe decoders, (the frame group size and window size, if pertinent) is chosen empirically to the values shown in Tables 1 and 2. Table 1Empirical q values for container.
Table 2Empirical q values for highway.
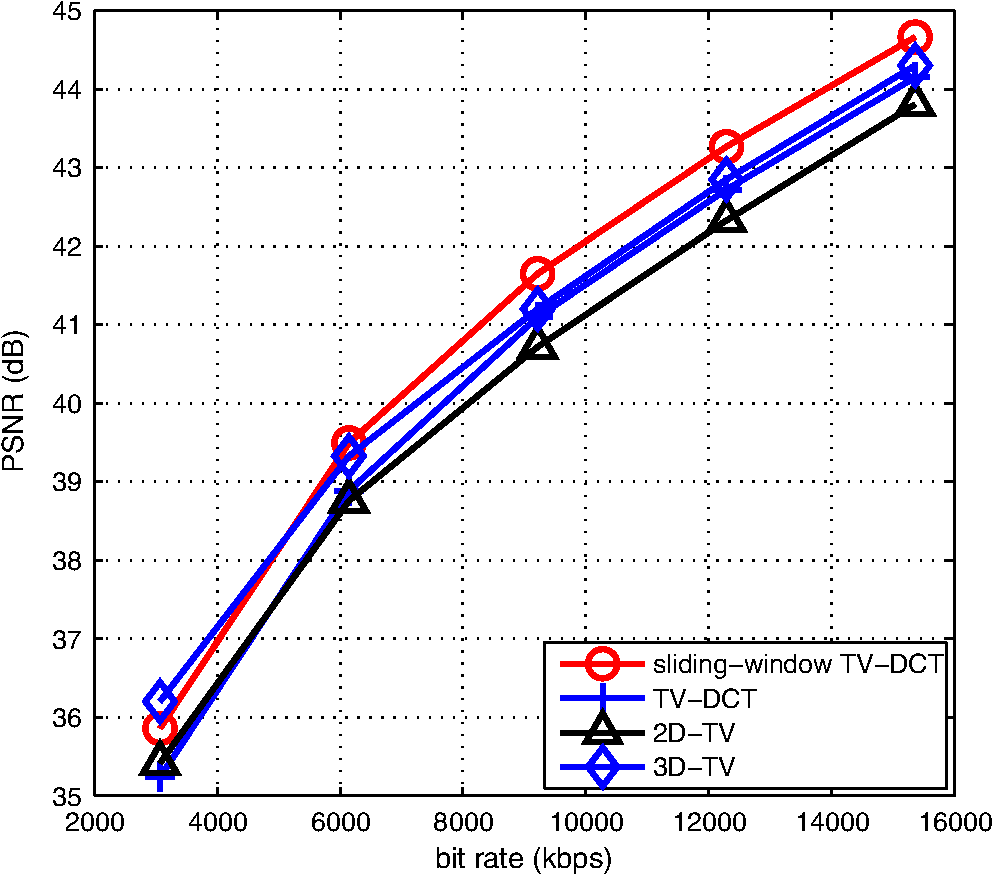
Figure 5 shows the decodings of the 28th frame of Container produced by the sliding-window TV-DCT decoder with varying and window size [Fig. 5(b)], the TV-DCT decoder with varying [Fig. 5(c)], the TV-DCT decoder with fixed [Fig. 5(d)], the 3D-TV decoder with fixed [Fig. 5(e)], and the 2D-TV decoder with fixed [Fig. 5(f)]. It can be observed that the 2D-TV decoder as well as the fixed TV-DCT decoder suffer noticeable performance loss over the whole image, whereas the varying sliding-window TV-DCT decoder demonstrates considerable reconstruction quality improvement. (As usual, pdf formatting of the present article tends to dampen perceptual quality differences between Fig. 5(a)–5(f) that are quite pronounced in video playback. Figure 6 is the usual attempt to capture average differences quantitatively.) These findings are consistent with the belief that varying , , in Eq. (16) results in a joint block-diagonal recovery matrix that is more likely to satisfy the restricted isometry property (RIP)3 for a given data sparsity level. Fig. 5Different decodings of the 28th frame of Container (). (a) Original frame. (b) Sliding-window TV-DCT (varying , ). (c) Plain TV-DCT (varying , ). (d) Plain TV-DCT (fixed , ). (e) 3D-TV (fixed , ). (f) 2D-TV (fixed ).  Figure 6 shows the rate-distortion characteristics of the five decoders for the Container video sequence. The PSNR values (in dB) are averaged over 100 frames. Evidently, the varying TV-DCT decoder outperforms the fixed TV-DCT decoder for all values, as well the fixed 2D-TV decoder at the median–low to high bit rate range with gains as much as 5 dB. The proposed varying sliding-window TV-DCT decoder further improves performance by up to an additional 2.5 dB. For the Highway sequence with fixed framewise CS acquisition, Fig. 7 shows the decodings of the 54th frame produced by the sliding-window TV-DCT decoder with window size [Fig. 7(b)], plain TV-DCT with group size [Fig. 7(c)], 3D-TV decoder with group size [Fig. 7(d)], and baseline 2D-TV decoder [Fig. 7(e)]. By Fig. 8, the proposed sliding-window TV-DCT decoder outperforms both the 2D-TV decoder and the 3D-TV decoder at median–low to high bit rate range, as well as the nonsliding-window TV-DCT decoder. 5.ConclusionsWe propose an interframe TV minimizing decoder for video streaming systems with plain framewise CS encoding. Each group of successive frames is jointly decoded by minimizing the TV of the pixelwise DCT along the temporal direction (TV-DCT decoding). To capture local motion across adjacent frames, a sliding-window decoding structure was developed in which a decoding window specifies the group of frames to be decoded. As the window continuously shifts forward one frame at a time, multiple decodings are produced for each frame in the video sequence, from which the average is taken to form the final reconstructed frame. Experimental results demonstrate that the proposed sliding-window interframe TV minimizing decoder outperforms significantly the intraframe 2D-TV minimizing decoder, as well as 3D-TV CS decoding schemes. In terms of future work, to further reduce our encoder/decoder complexity and maintain satisfactory video reconstruction quality, we may develop block-level CS video acquisition systems with rate-adaptive sampling at the encoder and measurement matrices of deterministic design to facilitate efficient encoding/decoding. AcknowledgmentsThis work was supported in part by the National Science Foundation (Grant CNS-1117121). ReferencesE. CandèsT. Tao,
“Near optimal signal recovery from random projections: universal encoding strategies?,”
IEEE Trans. Inform. Theory, 52
(12), 5406
–5425
(2006). http://dx.doi.org/10.1109/TIT.2006.885507 IETTAW 0018-9448 Google Scholar
D. L. Donoho,
“Compressed sensing,”
IEEE Trans. Inform. Theory, 52
(4), 1289
–1306
(2006). http://dx.doi.org/10.1109/TIT.2006.871582 IETTAW 0018-9448 Google Scholar
E. CandèsM. B. Wakin,
“An introduction to compressive sampling,”
IEEE Signal Proc. Mag., 25
(2), 21
–30
(2008). http://dx.doi.org/10.1109/MSP.2007.914731 ISPRE6 1053-5888 Google Scholar
K. Gaoet al.,
“Compressive sampling with generalized polygons,”
IEEE Trans. Signal Proc., 59
(10), 4759
–4766
(2011). http://dx.doi.org/10.1109/TSP.2011.2160860 ITPRED 1053-587X Google Scholar
E. CandèsJ. RombergT. Tao,
“Stable signal recovery from incomplete and inaccurate measurements,”
Comm. Pure Appl. Math., 59
(8), 1207
–1223
(2006). http://dx.doi.org/10.1002/(ISSN)1097-0312 CPMAMV 0010-3640 Google Scholar
R. Tibshirani,
“Regression shrinkage and selection via the lasso,”
J. Roy. Stat. Soc. Ser. B, 58
(1), 267
–288
(1996). 1369-7412 Google Scholar
B. Efronet al.,
“Least angle regression,”
Ann. Statist., 32
(2), 407
–451
(2004). http://dx.doi.org/10.1214/009053604000000067 ASTSC7 0090-5364 Google Scholar
J. TroppA. Gilbert,
“Signal recovery from random measurements via orthogonal matching pursuit,”
IEEE Trans. Inform. Theory, 53
(12), 4655
–4666
(2007). http://dx.doi.org/10.1109/TIT.2007.909108 IETTAW 0018-9448 Google Scholar
M. F. Duarteet al.,
“Single-pixel imaging via compressive sampling,”
IEEE Signal Proc. Mag., 25
(2), 83
–91
(2008). http://dx.doi.org/10.1109/MSP.2007.914730 ISPRE6 1053-5888 Google Scholar
S. PudlewskiT. MelodiaA. Prasanna,
“Compressed-sensing-enabled video streaming for wireless multimedia sensor networks,”
IEEE Trans. Mobile Comp., 11
(6), 1060
–1072
(2012). http://dx.doi.org/10.1109/TMC.2011.175 ITMCCJ 1536-1233 Google Scholar
I. E. Richardson, The H.264 Advanced Video Compression Standard, 2nd ed.Wiley, New York
(2010). Google Scholar
G. J. Sullivanet al.,
“Overview of the high efficiency video coding (HEVC) standard,”
IEEE Trans. Circ. Syst. Video Technol., 22
(12), 1649
–1668
(2012). http://dx.doi.org/10.1109/TCSVT.2012.2221191 ITCTEM 1051-8215 Google Scholar
V. StankovicL. StankovicS. Cheng,
“Compressive video sampling,”
in Proc. European Signal Proc. Conf. (EUSIPCO),
(2008). Google Scholar
M. B. Wakinet al.,
“Compressive imaging for video representation and coding,”
in Proc. Picture Coding Symposium (PCS),
(2006). Google Scholar
R. F. MarciaR. M. Willet,
“Compressive coded aperture video reconstruction,”
in Proc. European Signal Proc. Conf. (EUSIPCO),
(2008). Google Scholar
H. W. ChenL. W. KangC. S. Lu,
“Dynamic measurement rate allocation for distributed compressive video sensing,”
in Proc. Visual Comm. and Image Proc. (VCIP),
(2010). Google Scholar
J. Y. ParkM. B. Wakin,
“A multiscale framework for compressive sensing of video,”
in Proc. Picture Coding Symposium (PCS),
(2009). Google Scholar
Y. Liuet al.,
“Motion compensation as sparsity-aware decoding in compressive video streaming,”
in Proc. 17th Intern. Conf. on Digital Signal Processing (DSP 2011),
1
–5
(2011). Google Scholar
Y. LiuM. LiD. A. Pados,
“Decoding of purely compressed-sensed video,”
Proc. SPIE, 8365 83650L
(2012). http://dx.doi.org/10.1117/12.920320 Google Scholar
Y. LiuM. LiD. A. Pados,
“Motion-aware decoding of compressed-sensed video,”
IEEE Trans. Circ. Syst. Video Technol., 23
(3), 438
–444
(2013). http://dx.doi.org/10.1109/TCSVT.2012.2207269 ITCTEM 1051-8215 Google Scholar
L. RudinS. OsherE. Fatemi,
“Nonlinear total variation based noise removal algorithms,”
Physica D, 60
(1–4), 259
–268
(1992). http://dx.doi.org/10.1016/0167-2789(92)90242-F PDNPDT 0167-2789 Google Scholar
J. YangY. ZhangW. Yin,
“An efficient TVL1 algorithm for deblurring of multichannel images corrupted by impulsive noise,”
SIAM J. Sci. Comput., 31
(4), 2842
–2865
(2009). http://dx.doi.org/10.1137/080732894 SJOCE3 1064-8275 Google Scholar
E. CandèsJ. Romberg,
“1-magic: recovery of sparse signals via convex programming,”
(2005) http://users.ece.gatech.edu/justin/l1magic/downloads/l1magic.pdf Google Scholar
M. LustigD. DonohoJ. M. Pauly,
“Sparse MRI: the application of compressed sensing for rapid MR imaging,”
Magn. Reson. Med., 58
(6), 1182
–1195
(2007). http://dx.doi.org/10.1002/(ISSN)1522-2594 MRMEEN 0740-3194 Google Scholar
S. Maet al.,
“An efficient algorithm for compressed MR imaging using total variation and wavelets,”
in Proc. IEEE Conf. Comp. Vis. Pattern Recogn.,
1
–8
(2008). Google Scholar
C. Li,
“An efficient algorithm for total variation regularization with applications to the single pixel camera and compressive sensing,”
Rice University, Houston, TX,
(2009). Google Scholar
M. R. DadkhahS. ShiraniM. J. Deen,
“Compressive sensing with modified total variation minimization algorithm,”
in Proc. IEEE Intern. Conf. Acoustics Speech Signal Proc. (ICASSP),
1310
–1313
(2010). Google Scholar
C. Liet al.,
“Video coding using compressive sensing for wireless communications,”
in Proc. IEEE Wireless Commun. Networking Conf. (WCNC),
2077
–2082
(2011). Google Scholar
H. Jianget al.,
“Scalable video coding using compressive sensing,”
Bell Labs Techn. J., 16
(4), 149
–169
(2012). http://dx.doi.org/10.1002/bltj.20539 1089-7089 Google Scholar
H. GanapathyD. A. PadosG. N. Karistinos,
“New bounds and optimal binary signature sets—part I: periodic total squared correlation,”
IEEE Trans. Commun., 59
(4), 1123
–1132
(2011). http://dx.doi.org/10.1109/TCOMM.2011.020411.090404 IECMBT 0090-6778 Google Scholar
H. GanapathyD. A. PadosG. N. Karistinos,
“New bounds and optimal binary signature sets - part II: aperiodic total squared correlation,”
IEEE Trans. Commun., 59
(5), 1411
–1420
(2011). http://dx.doi.org/10.1109/TCOMM.2011.020811.090405 IECMBT 0090-6778 Google Scholar
Biography Ying Liu received the BS degree in telecommunications engineering from Beijing University of Posts and Telecommunications, Beijing, China, in 2006, and the PhD degree in electrical engineering from the State University of New York at Buffalo, Buffalo, New York, in 2012. Her research interests include video streaming, compressed sensing, and adaptive signal processing. She is currently an air traffic control engineer with ARCON Corp., Waltham, Massachusetts.  Dimitris A. Pados received the diploma degree in computer science and engineering from the University of Patras, Greece, in 1989, and the PhD degree in electrical engineering from the University of Virginia, Charlottesville, Virginia, in 1994. From 1994 to 1997, he held an assistant professor position in the Department of Electrical and Computer Engineering and the Center for Telecommunications Studies, University of Louisiana, Lafayette. Since August 1997, he has been with the Department of Electrical Engineering, State University of New York at Buffalo, where he is presently a professor. His research interests are in the general areas of communication theory and adaptive signal processing. He received a 2001 IEEE International Conference on Telecommunications best paper award, the 2003 IEEE Transactions on Neural Networks Outstanding Paper Award, and the 2010 IEEE International Communications Conference Best Paper award in Signal Processing for Communications for articles that he coauthored with students and colleagues. He is a recipient of the 2009 SUNY system-wide Chancellor’s Award for Excellence in Teaching and the 2011 University at Buffalo Exceptional Scholar—Sustained Achievement Award. |